
How to Get Started with Cron Job Monitoring: Our Complete Walkthrough

Quick Summary
Cron job monitoring keeps your scheduled backups and updates running reliably without causing disruptions. This guide walks you through how to set up monitoring, prevent failures, and simplify maintenance. With tools like Instatus, you can simplify cron job management, get real-time alerts, and stabilize systems with status page updates.
Not Sure How to Go About Cron Job Monitoring?
If you’ve ever relied on cron jobs to run backups, send notifications, or trigger workflows, you know how invisible they can feel. One missed run might go unnoticed until a customer complains, a database isn’t updated, or your app starts breaking in ways that are hard to trace.
For SaaS teams, DevOps engineers, and developers, the problem isn’t setting up cron jobs; it’s knowing when they fail before your users do.
In this Instatus article, we’re going to explain how to get started with cron job monitoring. We’ll walk you through the basics and show you how monitoring tools help keep your jobs visible and reliable.
But first…
Why Listen to Us?
At Instatus, we help thousands of SaaS and DevOps teams simplify how they manage cron jobs by providing clear monitoring, instant alerts, and easy-to-use status pages. Leading tech companies like Dovetail, Todoist, and Siemens rely on us to keep their automated tasks visible and reliable. With this hands-on experience, we’re well-equipped to guide you through getting started with cron job monitoring so your operations stay seamless and dependable.

What Is Cron Job Monitoring?
Cron job monitoring is the process of tracking and verifying whether your scheduled tasks (cron jobs) run as expected. A cron job is a time-based command used in Unix-like systems to automate repetitive tasks, like database backups, report generation, or sending notifications. Monitoring ensures these jobs don’t silently fail or run late without you noticing.
With cron job monitoring in place, you’ll receive alerts if a job doesn’t start, takes too long, or produces errors. This way, instead of waiting for users to flag problems, you can catch issues early and keep your systems running smoothly.
Why Cron Job Monitoring Is Important
- Task Reliability: Monitoring ensures that critical cron jobs run as scheduled and error-free.
- Early Failure Detection: Getting instant alerts via advanced monitoring tools like Instatus when a job fails, runs late, or produces unexpected results helps mitigate issues.
- Consistent System Performance: Quickly catch issues to keep operations smooth and minimize disruptions.
- Faster Team Collaboration: Monitoring integrates with tools like Slack or Microsoft Teams, making it easier for the right people to jump in, share context, and resolve issues quickly.
- Efficient Resource Management: Tracking job execution times helps optimize server loads, prevent overlaps, and reduce wasted resources.
How to Implement Cron Job Monitoring the Right Way
Step 1: Identify Critical Cron Jobs in Your System
Begin with a full audit of all scheduled tasks across your infrastructure. It’s common for organizations to find forgotten or undocumented cron jobs on different servers, managed by multiple teams. Without a clear inventory, you risk missing backups, incomplete updates, or unexpected downtime. To prevent this, document the following for each job:
- Purpose and business impact
- Schedule and frequency
- Dependencies (other jobs, APIs, or databases)
- Criticality to system stability
Pay special attention to tasks that directly affect system reliability, such as database backups, payment processing, data synchronization, and report generation. A practical way to approach this process is to:
- Export cron job configurations from all servers.
- Consolidate them into a central list or spreadsheet.
- Cross-check the list with application owners or teams.
- Flag jobs that are undocumented, duplicated, or rarely run but critical.
For instance, you can use this simple script to gather jobs across multiple servers:
# Loop through servers and dump cron jobs
for server in server1 server2 server3; do
echo "Cron jobs on $server:"
ssh $server "crontab -l"
done
This gives you a quick inventory to begin reviewing. From here, you can centralize, categorize, and decide what jobs need monitoring.
Step 2: Choose a Monitoring Tool
When it comes to monitoring cron jobs, you have two main options: manual scripts or SaaS tools.
Manual scripts offer full control, allowing you to customize checks, integrate them tightly with your internal systems, and track what’s important.
The downside is the overhead: manual setup takes a lot of time, requires continuous upkeep, and can be difficult to scale across multiple servers or teams.
Alternatively, SaaS monitoring platforms are ready out of the box. They typically provide:
- Website, API, Ping, TCP, and DNS checks
- Global monitoring locations
- Frequent intervals (as low as 30 seconds)
- Minimal maintenance and easy scaling

Among SaaS tools, Instatus stands out by combining comprehensive monitoring with built-in status pages and incident response features. Its seamless integrations let you connect existing cron job monitors, and real-time alerts keep your team instantly informed across channels like Slack or email. Its API also makes it easy to automate status page updates.
This all-in-one approach gives real-time visibility into your cron job health, keeps your team aligned, and notifies stakeholders promptly when issues occur.
Step 3: Set Up Heartbeat Monitoring
Even if a cron job is scheduled, you still need to confirm that it actually runs and finishes correctly. That’s where heartbeat monitoring comes in. Think of a “heartbeat” as a small signal your job sends to a monitoring service when it completes successfully. If the signal doesn’t arrive, it’s a clear sign the job failed or got stuck, so you can act quickly.
Setting up heartbeat monitoring with Instatus is simple. You can configure our API as endpoints for your cron jobs, such that each job sends a request to a designated URL when it finishes. You go beyond basic pings, configuring checks for extra validation, including:
- Response times
- Status codes
- Specific keywords
- JSON data integrity
Here’s how you could ping an endpoint on Instatus when a backup script finishes:
#!/bin/bash# Run backup/usr/local/bin/backup.sh# If successful, send heartbeat pingif [ $? -eq 0 ]; thencurl -fsS --retry 3 https://instatus.com/heartbeat/your-job-id > /dev/nullfi
You can also configure multiple checks per job to catch subtle failures that a single ping might miss. This gives you peace of mind that cron jobs are not only scheduled but also completing reliably.
Step 4: Configure Alert Channels
Before choosing a tool, decide how you want to be notified when a cron job fails. With Instatus, you can receive alerts through multiple platforms, including:
- Slack
- SMS
- Phone calls
- Other platforms like Microsoft Teams, Discord, or Google Chat.
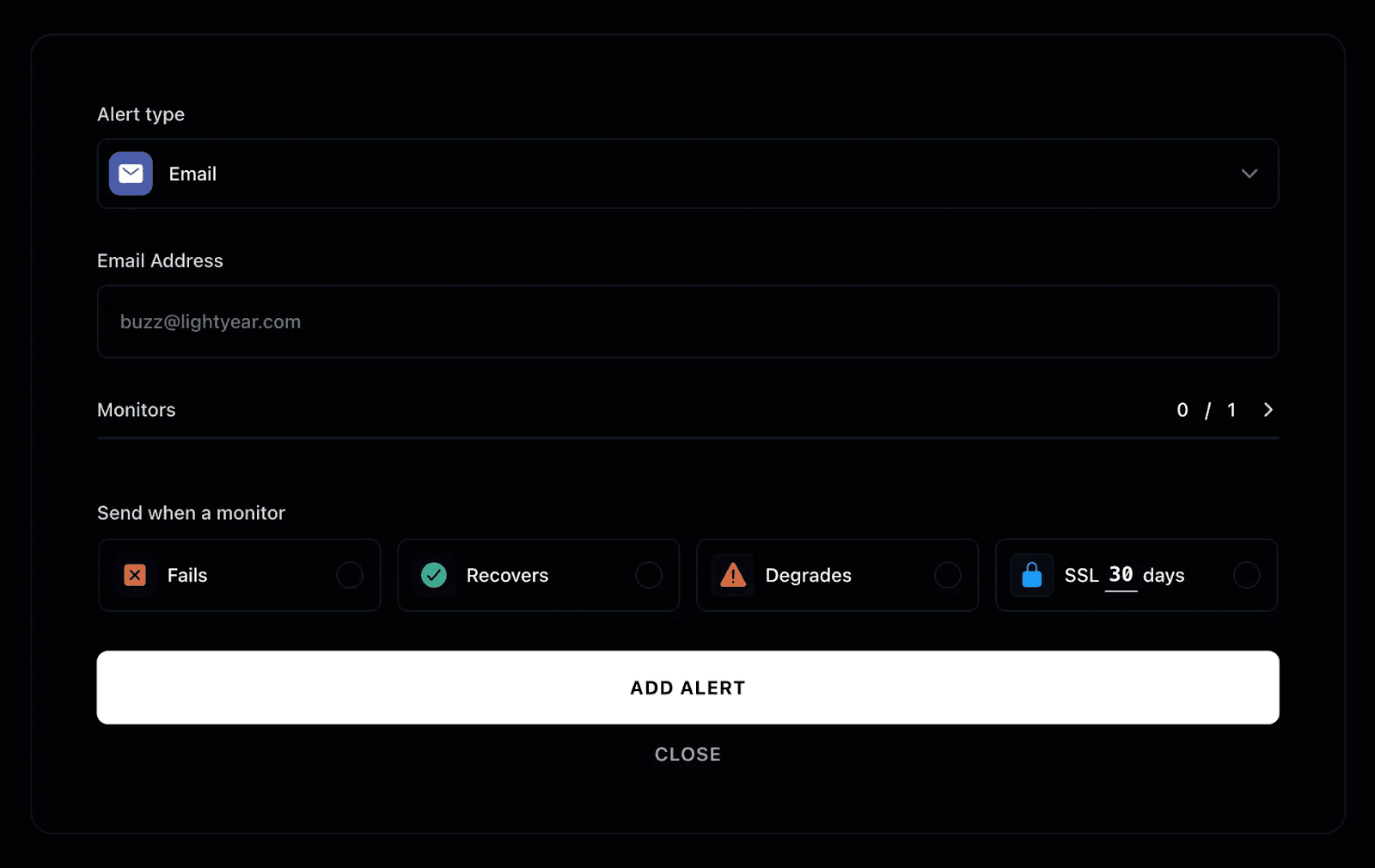
Set different channels for different severity levels so the right people are informed at the right time. Enabling on-call schedules and automatic escalation will also prevent critical issues from going unnoticed, even during off-hours.
You can also customize rules to differentiate minor delays from critical failures and track response times to catch slow jobs before they cause outages. This keeps your team proactive and your cron jobs running hitch-free.
Step 5: Test Cron Job Monitoring with a Dummy Job
Before going live with your setup, test endpoints by simulating successful and failed scenarios. This allows you to catch timeouts, HTTP errors, or slow responses before real issues arise.
Test common scenarios such as network hiccups, HTTP errors, or delayed cron job execution.. Confirm that your monitoring tool flags failures correctly and triggers alerts across all your selected channels.
Check the detailed logs for response bodies, headers, and performance metrics. These insights make troubleshooting easier and help you spot trends over time, ensuring your cron job monitoring is reliable.
Step 6: Keep Your Cron Job Playbook Clear and Updated
Clear documentation keeps job monitoring reliable and helps your team respond faster. Here’s how to build clear docs for cron jobs and alerts:
- Document Everything: Record all monitored cron jobs with their endpoints, expected responses, and troubleshooting steps in your team's knowledge base. Also include the schedule and criticality of each job.
- Create Runbooks: Include your monitor settings, alert thresholds, escalation procedures, direct links to dashboards, and performance data. This provides a fast path to action when issues come up.
- Review and Update Regularly: Schedule regular reviews (at least quarterly) of your configurations and alert thresholds. As systems grow, adjust system conditions to match new behaviors and baselines to keep your monitoring accurate and trustworthy.
Step 7: Connect to a Status Page for External Visibility
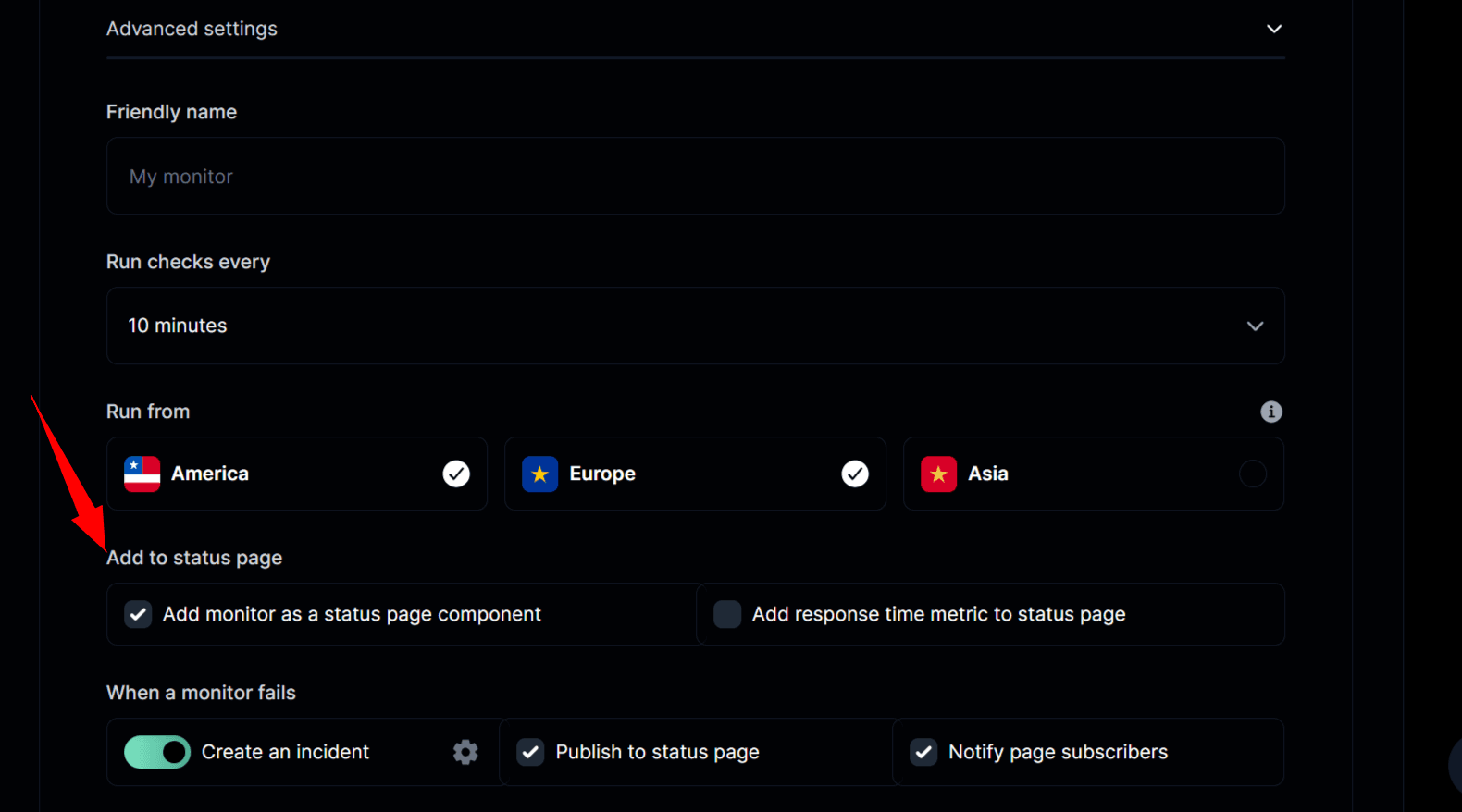
Keeping your team in the loop is key, but your customers also need clear updates. A public status page shows cron job health in real time and helps users understand service impacts. Here’s how to set this up on Instatus:
- Enable Automatic Updates: Turn on the "Add to status page" option in Instatus monitor settings to automatically display cron job health.
- Automate Incidents: Set Instatus to automatically publish incidents, notify subscribers, and resolve incidents when monitoring recovers. This keeps communication consistent during downtimes.
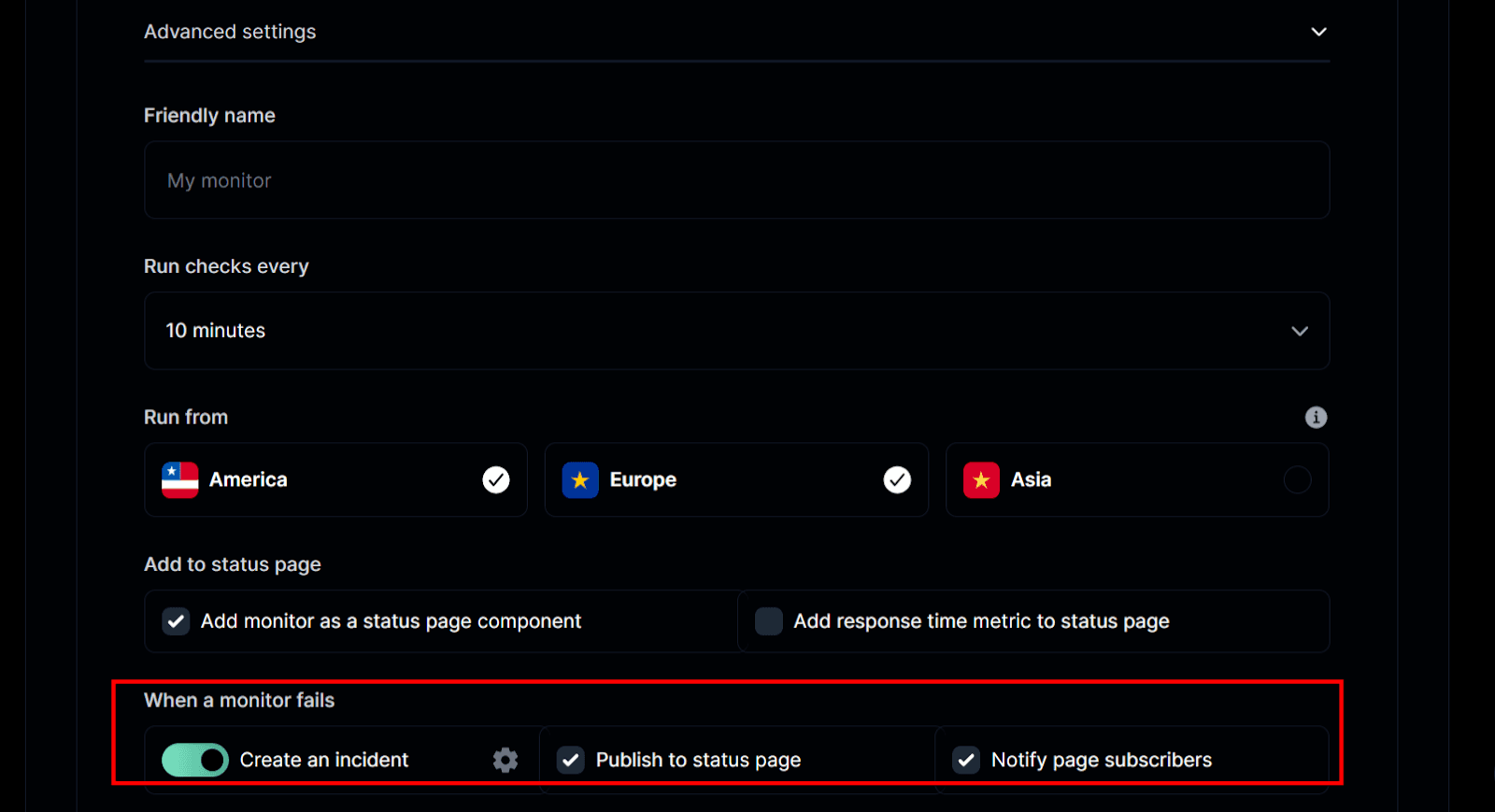
- Customize Messaging: Keep your updates professional and easy to understand without exposing sensitive technical details. Use Instatus's multilingual support and branding options to build customer trust during incidents.
Bonus Strategies for Effective Cron Job Monitoring
Once the basic steps are in place, the strategies below make your cron job monitoring more reliable, easier to act on, and more efficient:
1. Prioritize Critical Jobs First
Not all cron jobs have the same impact. Focus on the tasks that significantly affect your operations, customer experience, or compliance, like database backups, payment processing, and key data synchronizations. Prioritizing these reduces the risk of major disruptions and ensures monitoring resources are spent where they matter most. Reassess priorities regularly as new jobs are added or workflows change.
2. Diversify Alert Channels
Relying on a single alert method is risky, so set up multiple notification channels based on job severity and team responsibilities. Use custom alerts for different jobs to reduce noise and ensure critical issues reach the right people immediately, even outside office hours. Tools like Instatus make setting up multiple alert channels simple and reliable.
3. Test and Validate Regularly
Your monitoring setup is only useful if it actually works. Run dummy jobs to identify potential hiccups. Testing exposes blind spots and confirms alerts are firing correctly. Repeat this periodically to stay confident that your setup will catch real issues.
4. Use Version Control for Cron Scripts
Keep your cron job scripts in Git (or another VCS) just like application code. This makes it easier to roll back changes, track who updated what, and collaborate safely. It also helps spot changes that might have introduced errors.
5. Define Clear Job Thresholds
Set realistic limits for how long each job should take and what success should look like. This prevents false alarms and flags real issues affecting performance. Review thresholds periodically to ensure they stay aligned with evolving systems and processes.
6. Track Dependencies
Cron jobs rarely run in isolation. Monitor the APIs, databases, and other services your jobs depend on to detect upstream failures before they affect downstream tasks. Document them alongside performance benchmarks to speed up troubleshooting and maintain smooth operations.
7. Implement Circuit Breakers for Reliability
Add circuit breakers to prevent cascading failures in your cron jobs. If a dependent service is down, the circuit breaker halts retries and alerts your team instead of hammering the system and making things worse. This keeps downstream jobs stable.
8. Optimize Schedules Regularly
Review job timings to prevent overlaps, remove redundancy, and reduce server strain. Adjust schedules as workloads shift to ensure tasks run efficiently and on time. Tracking trends over time can uncover conflicts or inefficiencies. Regular optimization ensures your system is running reliably and minimizes surprises.
9. Name Cron Jobs Meaningfully
Descriptive names make it easier to identify issues and communicate across teams. Include context like frequency or dependencies to improve clarity. Avoid vague labels such as “job1” or “taskA,” which slow down troubleshooting. Clear naming also makes dashboards and reports easier to interpret at a glance.
10. Keep Historical Logs for Analysis
Store logs and monitoring data consistently to identify recurring problems, performance trends, and potential bottlenecks. This information becomes insight that supports informed decisions, helps fine-tune thresholds, and optimizes job schedules. By analyzing past runs, your team can improve reliability and prevent future failures.
11. Secure Your Cron Jobs
Don’t overlook security. Store credentials in environment variables or secret managers, not hardcoded scripts. Restrict permissions to only what’s necessary. Monitoring security-related cron jobs (like log rotations or patch checks) also helps reduce risk.
Streamline Cron Job Monitoring with Instatus
Cron job monitoring ensures your scheduled tasks run on time and without errors. By tracking execution, setting alerts, and reviewing logs, you can prevent downtime and maintain system reliability.
Instatus makes it easy to monitor the services and endpoints your cron jobs rely on. With real-time monitoring, automated alerts, and customizable status pages, you’ll catch potential failures early, keep teams and customers informed, and reduce the stress of manual oversight.
Get started with Instatus today — It’s FREE..

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers