
What Is a Cron Job? Our Beginner's Guide to Automating Server and App Tasks

Quick Summary
This article breaks down cron jobs, automated server tasks that save time, boost reliability, and cut costs. We explored how to set them up, common monitoring challenges, and best practices like prioritizing critical jobs, setting up smart alerts, logging outputs, optimizing schedules, and testing before deployment.
Wondering What Cron Job Means and How it Can Save You Time?
If you’ve ever stayed up late just to restart a server, trigger a backup, or run a script at the “right” time, you know how frustrating and error-prone manual work can be. For DevOps teams and developers, these small but recurring tasks pile up, stealing focus from building features and fixing real issues. That’s where cron jobs come in.
In this Instatus article, we’ll explain what a cron job is, how it works, and why it’s a must-have for automating server and app tasks. You’ll also see real-world examples and best practices so you can run smoother operations with less stress.
But first…
Why Listen to Us?
At Instatus, we help thousands of SaaS and DevOps teams simplify how they manage cron jobs by providing clear monitoring, instant alerts, and easy-to-use status pages. Leading tech companies like Dovetail, Todoist, and Siemens rely on us to keep their automated tasks visible and reliable. This hands-on experience gives us the expertise to break down what cron jobs are and how you can use them to run smoother operations.

What Is a Cron Job?
A cron job is an automated task that runs on your server at a scheduled time. Instead of manually running scripts or commands, you can set up cron jobs to handle them for you, whether it’s every minute, once a day, or only on specific dates.
Cron jobs are powered by a tool called cron, a time-based job scheduler in Unix-like operating systems. Think of it as your server’s personal assistant. You tell it what to do (the command), and when to do it (the schedule), and it executes the task without you having to lift a finger.
For example, you might use a cron job to:
- Back up your database every night at midnight
- Clear temporary files once a week
- Send automated email reports every morning
- Restart a service if it crashes
Benefits of Cron Jobs
Automation and Consistency
Cron jobs automate repetitive tasks like backups, log rotations, and data syncing, ensuring they run at the exact time you set. Couple this with an Instatus monitor, and you’ll know immediately if one fails or is delayed. This consistency builds trust that critical processes aren’t slipping by unnoticed.
Resource Optimization
By scheduling heavier jobs during off-peak hours, cron helps balance workloads and keep systems responsive. This smart scheduling prevents bottlenecks, improves system performance, and keeps infrastructure running efficiently.
Cost Reduction
Automating manual tasks cuts down on operational costs and prevents small issues from snowballing. With Instatus alerts and status pages, failures are visible right away, teams are notified instantly, and customers can check the status themselves. This reduces ticket volume, speeds up resolution, and keeps costs under control.
See our guide to cost per ticket and how to reduce it.
Improved Efficiency
Since cron jobs run automatically, your team no longer has to waste time on repetitive checks. Engineers can focus on solving real problems instead of digging through logs, making workflows smoother and more productive.
Scalability
As your systems grow, cron jobs grow with them. You can manage tasks across multiple servers without losing control, ensuring your operations scale smoothly with your business needs.
How to Set Up and Monitor Cron Jobs the Right Way
Here’s a quick look at how cron jobs run, how to set them up, and keep an eye on them with monitoring and alerts:
1. Set Up a Cron Job
A cron job is made up of two main parts:
- The Cron Command: The script or command you want to run.
- The Schedule: The exact time the command should be executed.
The cron job’s schedule is set in the crontab using a simple five-field format:
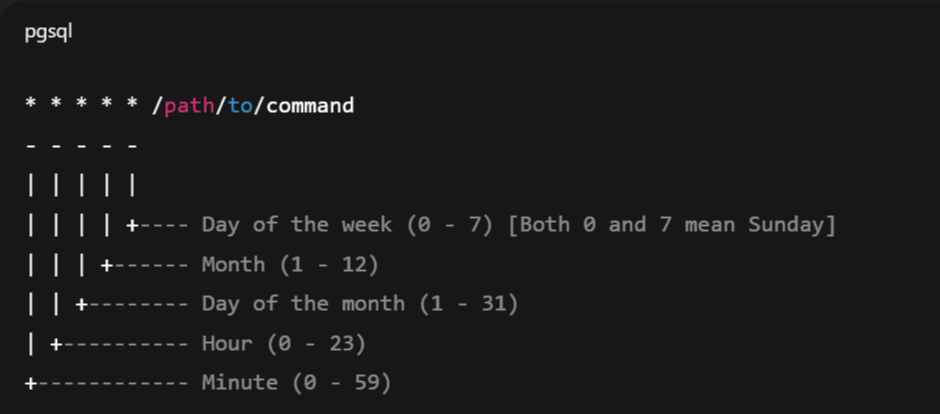
Each field represents a specific unit of time (minute, hour, day, month, and day of the week), and by entering numbers into them, you set the exact time for the job to run.
Examples:
0 2 * * */path/to/backup.sh- Runs the backup.sh script every day at 2:00 AM.*/15 * * * */path/to/check.sh— Runs the check.sh script every 15 minutes.30 6 1 * */path/to/report.sh— Run report.sh on the 1st of every month at 6:30 AM.
Once you've defined your cron job, the cron daemon (crond) starts running in the background, checking crontab entries by the minute for any tasks to execute. If the current time matches a rule, crond will execute the corresponding command in a shell environment.
Pro Tip: Cron jobs don’t run with the same environment variables as your interactive shell.
- Always set absolute paths (/usr/bin/python3 instead of python3)
- Redirect logs (>> /var/log/backup.log 2>&1) to avoid silent failures
2. Monitor Your Cron Jobs Locally
Cron jobs run in the background, making it easy to forget about them. That’s why it's important to consistently monitor their success or failure. By default, cron can email the output of a job to the system user so that you can keep an eye on things, but this isn’t scalable when you’re managing dozens of jobs across multiple servers.
See our article on the difference between monitoring and observability.
Common challenges that you may face include:
- Silent Failures: Jobs that exit with errors but don’t notify anyone.
- Resource Overruns: Scripts that hang or run longer than expected.
- Distributed Complexity: Different servers running independent jobs without centralized visibility.
Without monitoring, a failed database backup or overdue cleanup script might not be discovered until downtime occurs. These blind spots make it essential for teams to look beyond cron’s default setup for better visibility.
3. Add a Monitoring and Alerts Service
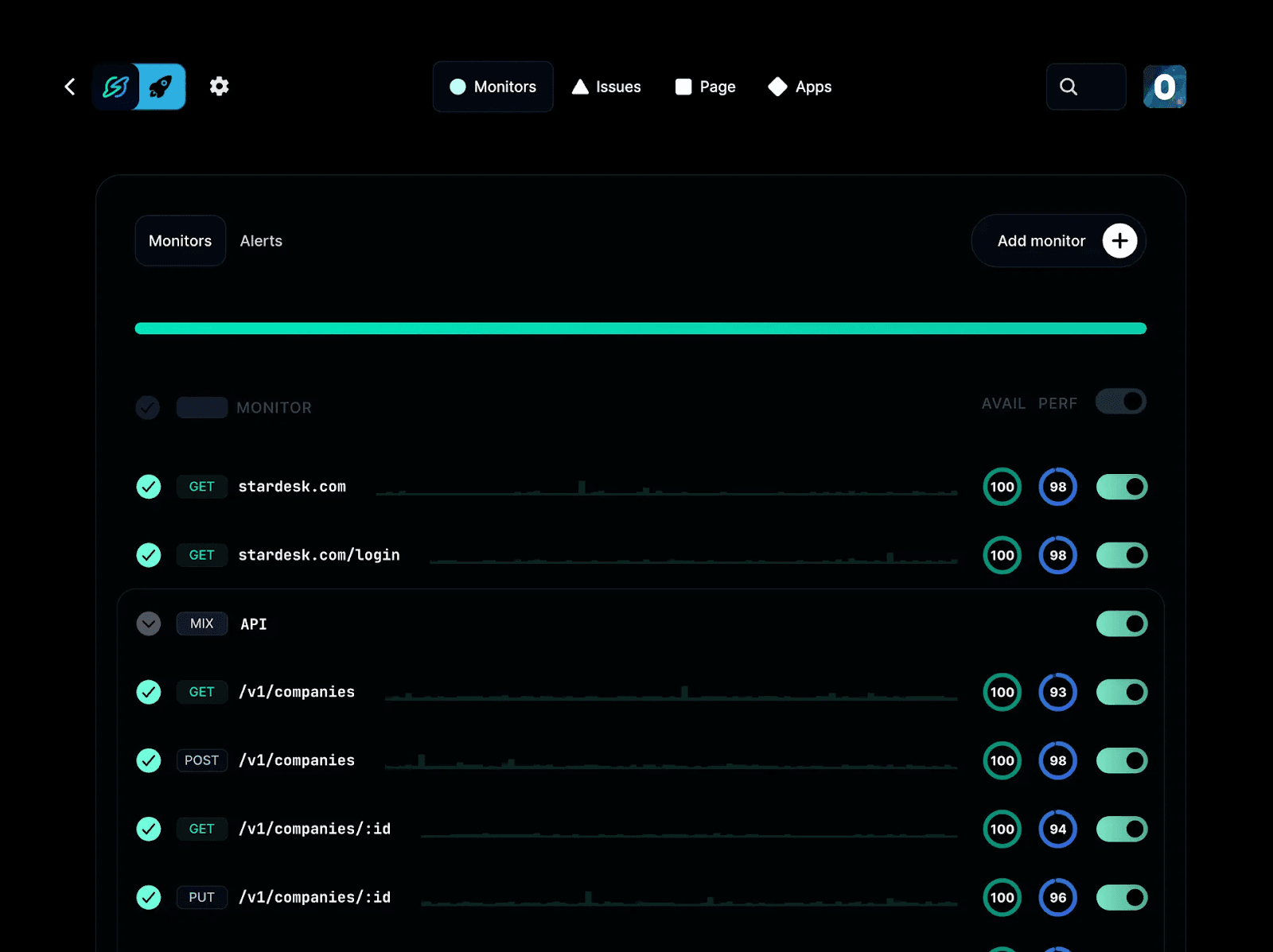
Pairing cron with a dedicated monitoring and alerting platform like Instatus strengthens cron job management. Instatus fills the visibility and reliability gap by tracking jobs in real time, alerting your team when something fails, and keeping stakeholders informed with live status updates.
Here’s a breakdown of how Instatus helps:
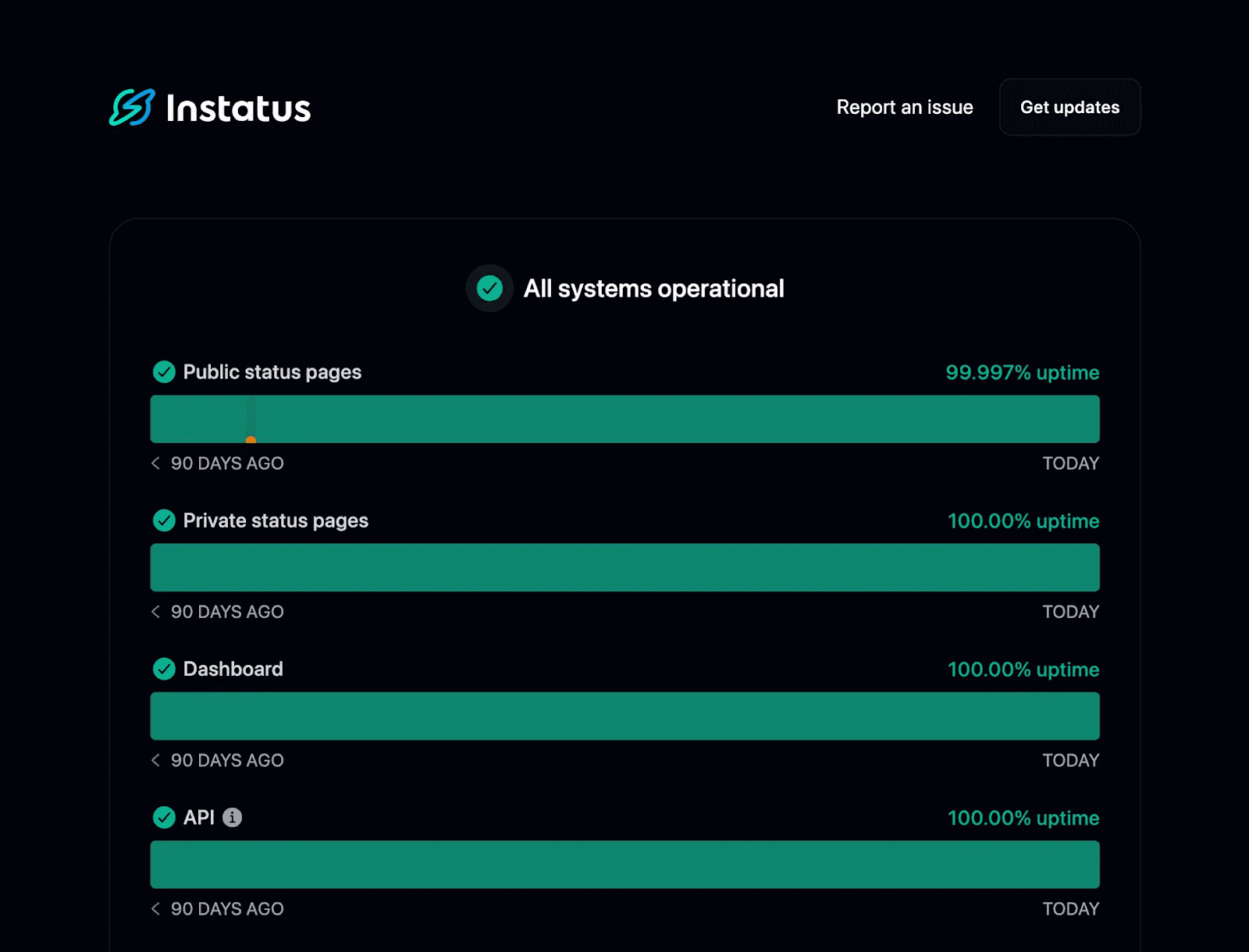
- Status Page Integration: When a cron job fails (for example, a database backup doesn't complete), Instatus can automatically update your status page with an incident, informing both your team and customers about the issue.
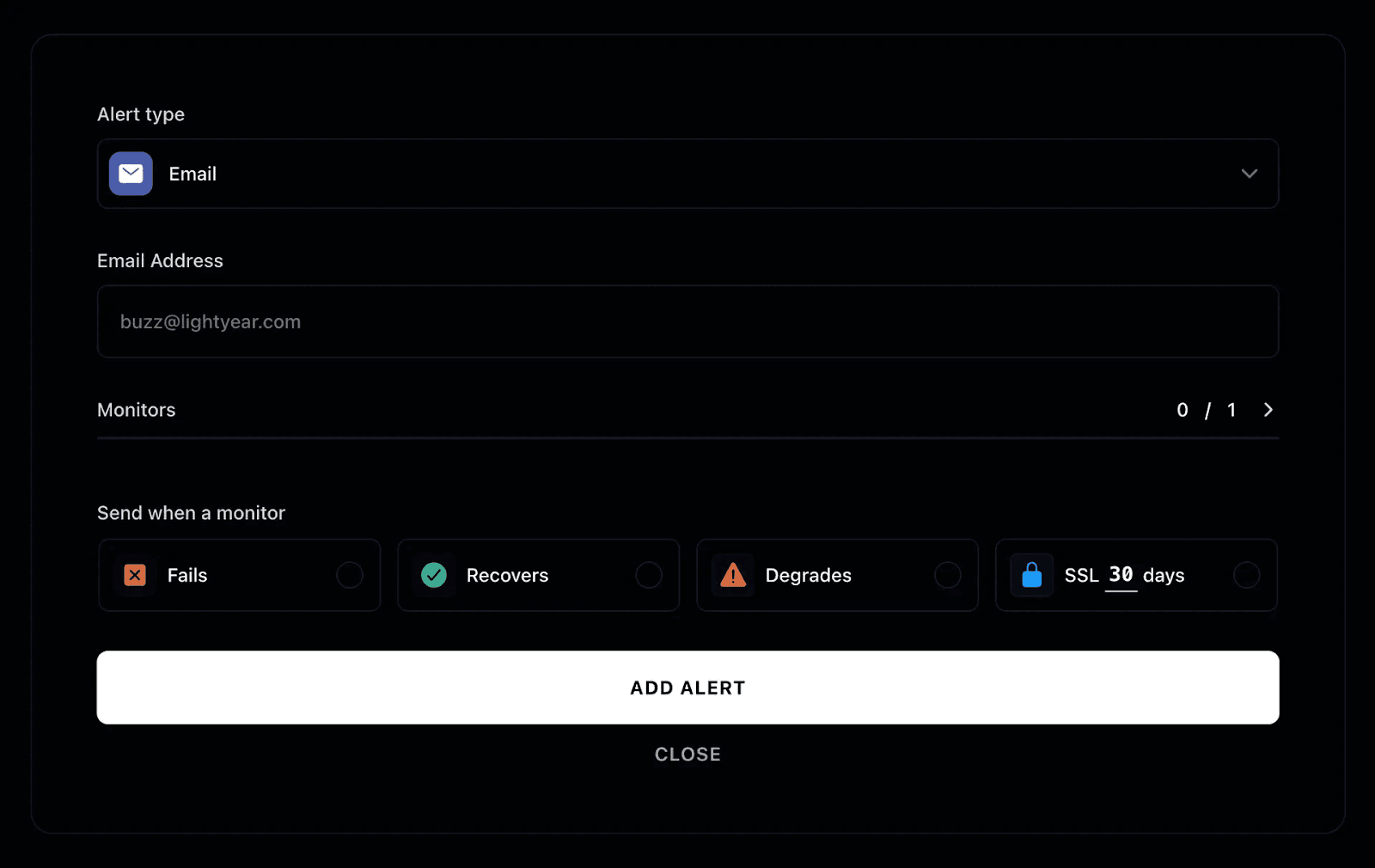
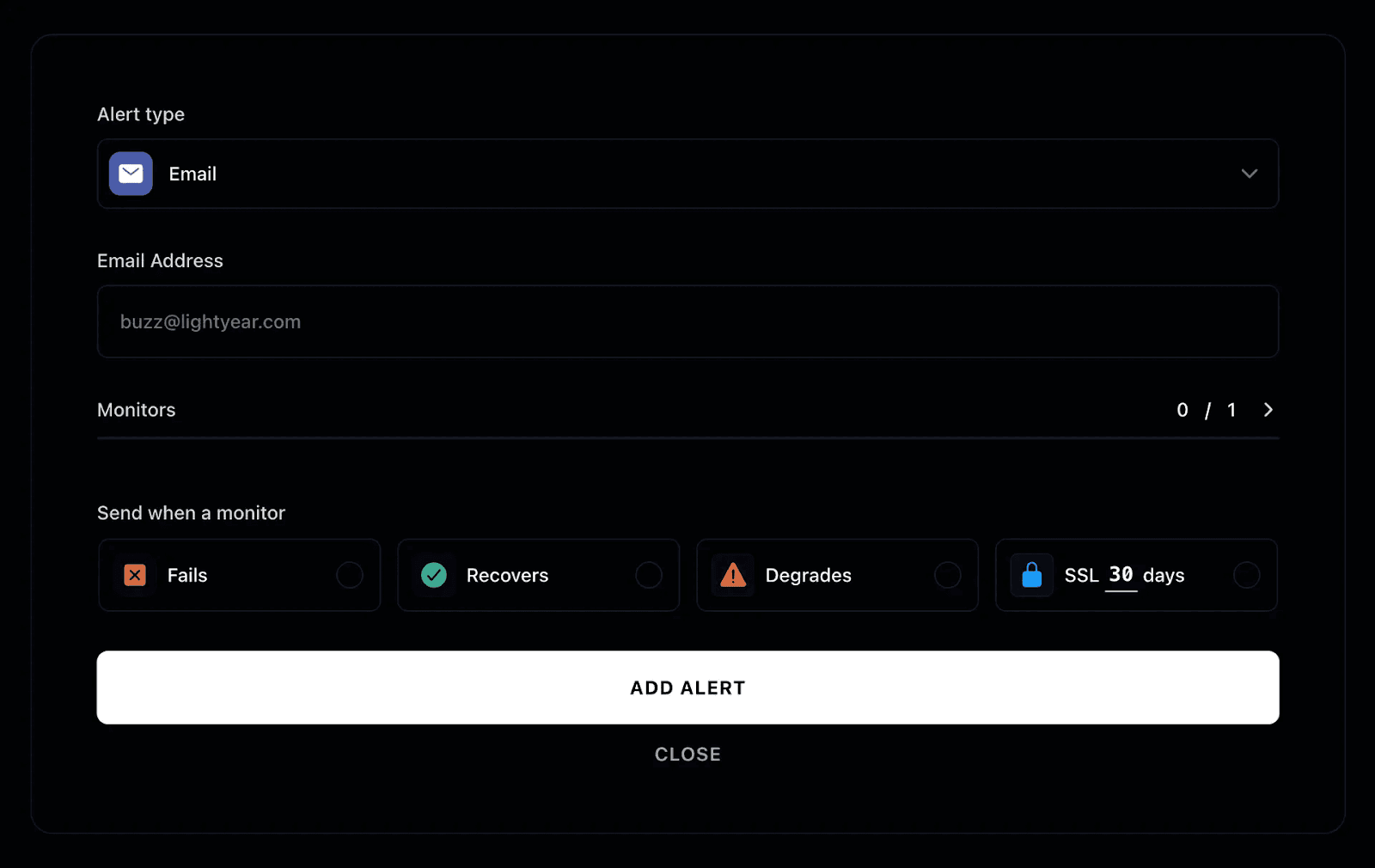
- Real-Time Alerts: Instatus integrates with Slack, email, or SMS, allowing you to set up notifications that alert you the moment a job fails. This enables faster troubleshooting and response time, ensuring you catch and resolve issues before they become outages.
- Performance Tracking: By default, cron only tells you whether a job was triggered, not if it completed successfully. That means failures, errors, or unusually long runtimes can slip under the radar. Instatus helps fill this gap by letting you set up monitors that check whether your jobs actually respond as expected.
For example, by verifying an API endpoint, checking response codes, or watching for certain keywords in the output. You’ll get alerts if something looks wrong, and you can even use the Instatus API to push custom success/failure signals from your cron jobs.
Best Practices for Implementing Cron Job Monitoring
Following these best practices ensures your cron jobs run reliably, scale smoothly, and don’t create hidden problems down the line.
Prioritize Critical Job Identification
Not every cron job is created equal. Start by mapping out which tasks are critical to your business, such as database backups, payment processing, or system cleanups. These should be your highest monitoring priority since their failure can directly affect uptime, customer trust, or revenue.
Set Up Smart Alerts
Alerts should be actionable, not noisy. Configure thresholds that distinguish between minor hiccups and major issues, and direct alerts to the right team members. With a tool like Instatus, you can route real-time notifications to Slack, email, or SMS, and even update your status page automatically so your team and users stay informed without opening unnecessary support tickets.
Implement Logging and Visibility
Always redirect cron job outputs and errors into logs instead of letting them vanish silently. Centralized logging makes it easier to trace failures, troubleshoot root causes, and maintain historical records of job performance. Pairing logs with dashboards or monitoring tools ensures you’re never left guessing what happened when something goes wrong.
Review and Optimize Regularly
As your infrastructure evolves, so should your cron jobs. Periodically audit job schedules, commands, and dependencies to remove redundancies or outdated tasks. Optimization prevents wasted compute resources and reduces the risk of overlapping jobs that can degrade performance.
Test Before Deployment
Before adding a new cron job to production, run it in a staging or test environment. This ensures it behaves as expected and doesn’t conflict with existing jobs. Testing reduces the likelihood of introducing instability or errors into your live systems.
Stay Ahead of Cron Job Failures with Instatus
Cron jobs are powerful for automating routine tasks, but managing and monitoring them across growing systems can get complicated quickly.
That’s where you’ll find Instatus invaluable. By combining automation with real-time monitoring, smart alerts, and transparent status updates, Instatus makes cron job management simple and reliable. You’ll catch failures before they become outages, keep teams and customers informed, and reduce the stress of manual oversight.
If you’re ready to stay ahead of downtimes and cron job failures the smarter way, try Instatus today—it’s FREE.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers