
Key Differences Between SRE and DevOps

Is it really necessary to have both DevOps engineers and Site Reliability Engineers? They do the same thing, right? Wrong.
DevOps and SRE are related, but their problems, customers, goals, and approach to failure are different. DevOps focuses on creating high-quality applications from beginning to market. On the other hand, SRE solves infrastructure and IT problems to create reliable IT systems. These two disciplines feed into each other, DevOps create software and SRE helps manage the systems that run the software.
So there’s tremendous value in having both types of engineers working for your organization. While Dev and Ops teams work on pushing out frequent deployments, an SRE will help improve your application uptime. Plus, a site reliability engineer can manage your Instatus status page during outages, keeping your users updated on the status of incidents.
What is SRE?
SRE or Site Reliability Engineering is a branch of engineering focused on improving equipment reliability for long-term system health. Ben Treynor Sloss first introduced the SRE approach in 2003. Sloss is now Vice President of Google Engineering. An ebook is available if you’re interested in Google’s approach to and experiences with SRE.
Site Reliability Engineering (SRE) applies software engineering principles to information technology operations. It is often about meeting service-level agreements (SLAs), which is a predetermined level of service expected by an organization. SLAs are the main backbone of the contract between an organization and an IT vendor.
An organization may get a service discount when reliability falls below expected levels. Larger companies, like Google, may have internal SRE teams to assist and improve operations.
What is the Role of a Site Reliability Engineer?
A reliability engineer is tasked with solving operations problems from a software perspective. Site Reliability Engineers are responsible for tracking and monitoring latency, performance, availability, and other metrics.
Monitoring, logging, configuration management, metrics, and automation are the primary components of an SREs toolkit. They use these tools and metrics to identify pain points and areas of concern for Ops teams.

Automating Operations Solutions
Reliability engineers work to build tools and services that reduce the operations workload. The main workflow behind SRE is about finding a problem, solving the problem, and then automating the solution so that you don’t have to return to this problem again.
SREs are focused on developing IT systems that can hold up for the long-term, with high reliability and scalability to be flexible towards a business’s needs.
Support Tickets
Besides finding solutions to Ops IT problems, Site Reliability Engineers spend their time handling escalation support tickets. Support tickets are another great source of ideas for SREs. As SRE teams continually integrate and deploy operations solutions, the IT systems will become much more reliable. A promising sign that the team is targeting the correct problems and improving reliability is a declining number of support escalations.
Post-Incident Review
Following an outage or service interruption, SREs will engage in a post-incident review to determine what happened and how to prevent it from happening again. Postmortems are vital for SREs and bring multiple teams together to assess how an incident played out. Post-incident reviews ask questions like:
- Were the impacts of the incident minimized?
- Were there any barriers to resolving the incident promptly?
- Was everyone notified in a timely manner?
- How long did it take for on-call team members to receive a notification of the incident and then respond?
- Were any third-party contractors needed to solve the incident?
- What was the root cause of the failure?
SREs can gain invaluable information on operational systems and make suggestions for improvements. Beyond the SRE team, a PIR can be summarized (when appropriate) on a public-facing website like Instatus, to build trust in the reliability of your product. Placing all outage communication in a centralized location, like a status page, lets your users know where to go when they’re having issues with your products.
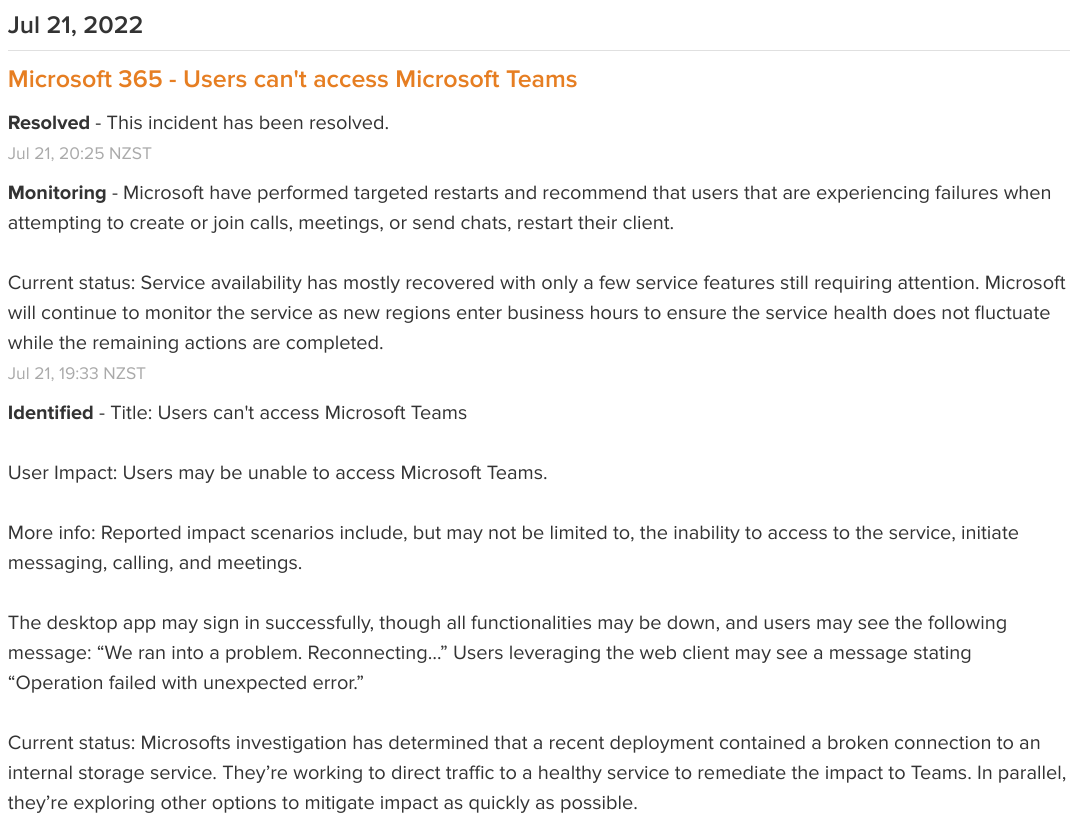
Take this example of an actual Instatus page from New Zealand IT company OneCall that includes incident updates like monitoring, identified, and resolved. You can see how to keep your customer’s in the loop as an incident progresses:
What is DevOps?
DevOps is a software development methodology that combines development and operations teams in a more unified way to support the entire SDLC. By removing the barriers from these historically siloed departments, these two teams can collaborate more closely and work together to create better software products.
Development teams still handle most of the coding and application development, while Ops teams are responsible for deploying and managing the application. DevOps has only been around for about 15 years but has proven very effective at developing high-quality applications.
Continuous integration and deployment, automation, continuous improvement, and collaboration are the core tenets of DevOps. Dev teams gain a better understanding of the role of Ops and learn how to develop an application with operations in mind. Ops works closely with developers throughout the SDLC to try to accommodate the ideas and intentions of developers when possible.
What is the Role of a DevOps Engineer?
DevOps Engineers are focused on continually improving the entire SDLC from the earliest stages to deployment and maintenance. A DevOps Engineer is responsible for understanding the product and finding new tools and processes to make the development process proceed more smoothly and efficiently.
DevOps Engineers are familiar with monitoring tools, automation tools, code review processes, IT infrastructure, production environments, and application deployment. They help design the strategies that make DevOps so successful as a software development methodology.
What are the Differences between SRE and DevOps?
DevOps and SRE can seem similar, but some critical distinctions exist. Many principles that make DevOps exceptional, like automation, monitoring, and continuous improvements, are also key aspects of Site Reliability Engineering. But now, let’s shift to discuss three differences between SRE and DevOps:
1. Different Goals
A key difference between DevOps and SRE is the day-to-day problems that these engineers are working through. DevOps is trying to solve the inherent problems created by the software development life cycle. DevOps objectives include:
- Accelerating development time/ increasing change rate
- Increasing customer satisfaction
- Automating integration and deployment
- Increasing deployment frequency
Notice the clear focus on productivity, efficiency, and speed in the problems DevOps is trying to solve. SRE is not focused on speed and efficiency, although SRE teams often automate IT operations processes that waste the time of system administrators. Instead, Site Reliability Engineers focus on reliability and problem-solving. The problems that SREs face include:
- Resolving operations incidents
- Automating manual processes
- Setting up monitoring, logging, and diagnostics for IT systems
- Handling tickets
- Improving overall reliability
2. Different Customers
Of course, the ultimate customer is always the end-user, but REs have a different customer in mind. SREs are often contractors, yet even when you’re working with an internal SRE team, they are focused on the needs of operations. SREs want to improve IT systems' reliability and limit system administrators' workload. Site Reliability Engineers must meet the standards set by their SLA to make their customer happy.
Application stakeholders and end-users are the primary customers of DevOps teams. If your team is developing an internal software product, you are trying to make an excellent application that meets the user's expectations.
You’re concerned with developing features and UI that perform well and make users happy to use your product. There are no hard-line SLA’s, but there is likely a list of essential features for the final product.
3. Team Structure
In a DevOps environment, there are no distinct DevOps teams per se; rather, it's a set of practices and principles adopted by development and operations teams. These teams work together throughout the software development lifecycle, from planning and coding to testing, deployment, and monitoring.
Oftentimes, a DevOps team might consist of developers, system administrators, QA engineers, and other experts, all working together to deliver and maintain the software. The aim is to foster communication and cooperation to ensure that code is efficiently developed, tested, and deployed with a focus on automation and continuous integration and delivery.
While SRE is a more specialized role within an organization. They are often considered an evolution of traditional operations or system administration roles. The SRE team is composed of engineers who possess a deep understanding of software development and system operations. They focus primarily on ensuring the reliability and availability of services and infrastructure. SRE teams collaborate closely with development teams to set and achieve reliability goals, define Service Level Objectives (SLOs), and establish error budgets.
The SRE team is responsible for building and managing tools and systems to monitor service health, respond to incidents, and automate operations tasks. They aim to strike a balance between stability and new feature development and have a strong focus on managing risks and reducing downtime.
In essence, Both approaches aim to improve software delivery and operations, but they have different team structures and areas of expertise.
4. Practical Application
DevOps is a widely adopted approach in agile software development projects, serving as a stimulus for seamless collaboration among cross-functional teams. By breaking down silos, DevOps enables developers, operations personnel, and other stakeholders to work in sync, leading to faster and more efficient software delivery. It emphasizes the continuous integration and continuous delivery (CI/CD) pipeline, automating repetitive tasks, and implementing rigorous testing procedures to ensure a stable and reliable software product.
On the other hand, SRE takes center stage in lean infrastructure practices. SREs are the ones responsible for designing, building, and operating systems that support software applications. Their primary focus revolves around maintaining system stability, scalability, and reliability. SREs closely monitor system performance, identifying potential gaps and areas for improvement. By utilizing data-driven insights and analytics, they fine-tune system configurations to optimize performance and enhance user experience.
While both DevOps and SRE contribute to the overall success of software projects, their core functions differ significantly. DevOps focuses on the integration of development and operations, while SRE aims for effective management of systems and infrastructure, striving for maximum uptime, performance, and stability.
5. Metrics and Indicators
In DevOps, success is often measured by how smoothly and quickly software is developed and deployed. Metrics like deployment frequency, lead time for changes, and time to recover from incidents are used to assess how quickly and reliably new features and updates are delivered to users. These metrics are focused on improving collaboration and efficiency between development and operations teams.
SRE takes a different approach by using Service Level Objectives (SLOs) as an indicator to measure the health and reliability of services. SLOs set specific targets for service performance and uptime that a service should achieve to meet user expectations. SRE's main goal is to maintain a service that consistently meets or exceeds these targets to ensure users get a dependable and high-quality experience.
While both DevOps and SRE aim for high-quality services, DevOps emphasizes the development and delivery process, while SRE focuses on maintaining service reliability and availability through well-defined objectives.
6. Approach to Failure
DevOps is open to failure, while SRE is not. DevOps welcomes failure by trying new processes and figuring out what works and what doesn’t. DevOps culture also promotes a blameless approach to failure. This encourages experimental approaches to solving problems and breeds innovation.
Site Reliability Engineers are working under different circumstances. They must meet the reliability and expectations of any Service Level Agreements or Service Level Obligations. This means the mistakes have much greater implications for SREs. Site Reliability Engineers don’t want any failures because this means they might miss their availability targets. SREs spend less time experimenting and more time developing robust tried-and-true IT systems.
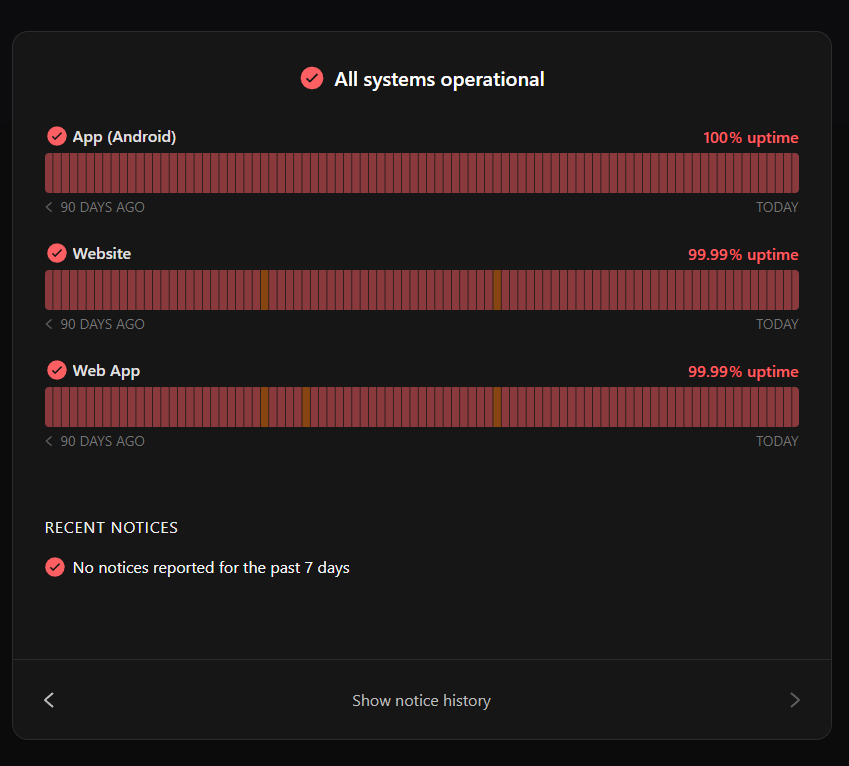
Failure is part of the SRE process, but engineers want to build systems that quickly detect and contain failures. When these systems do fail, there’s no hiding from it. Customers can easily see the uptime on Instatus for the last 90 days. Most organizations want an uptime of 99.9%, which means only 8.7 hours of downtime over 365 days.
DevOps & SRE Best When Combined
Because DevOps and SRE work towards different ends, the best approach is to combine both disciplines. 50% of companies are already using SRE, while 77% of organizations have adopted the DevOps methodology. DevOps methodology will help create a higher-quality software product to send down the pipeline, with faster timelines.
When Site Reliability Engineers can work with Operations to support a high-quality application they can really work on creating stable reliable systems, instead of trying to work with poorly designed applications. As time goes on, the number and duration of incidents should decrease. Instatus will continue to serve as a backup for those unexpected incidents, which everyone in this field is familiar with.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers