
Why your Business Should Invest in a Post Incident Review Process

Yikes, that outage affected 50,000 customers and cost the company $1 million dollars. That’s not something you want to experience again, but at least it’s over. What now?
Post-incident reviews follow a high severity or critical incident. A post-incident review is an evaluation of your response and recovery, and it assesses the time between the incident and resolution. This process looks at all actions and reactions of the incident management response team.
The post-incident review process often culminates in an incident report that provides the findings and gives feedback for handling the next high severity incident. For example, a review may find your team is missing critical awareness of the status of your services and recommend a solution like Instatus to reduce this blind spot.
A post-incident review will keep your team from returning to business as usual following an incident and require you address issues.
What are the Goals of a Post-Incident Review?
Ideally, your team should begin a post-incident review within 24 hours of an event as memories are at their best in this time frame.
To prepare for a post-incident review, you need to outline your goals. For example, what does your organization wish to accomplish with the post-incident review process? Consider each of the goals listed below and select the ones that make sense for your organization:
- Reduce the detection time of the initial incident
- Could this incident have been detected sooner?
- Are you missing any triggers or monitoring software like Instatus that could prevent this from happening next time?
- Prevent this incident from occurring again
- What barriers can you add to prevent this incident from reoccurring?
- What failed first? Was there any critical oversight?
- Did you learn something new about your organization’s systems?
- Improve the time required to diagnose the cause of the incident
- How long did it take your team to diagnose what caused the incident?
- Was there information missing that prevented a more rapid diagnosis?
- Does your team need to implement new tools or processes?
- Review recovery actions and make recommendations to reduce inefficiencies or missed opportunities for faster recovery
- Did your team miss any important steps that slowed recovery?
- Was your team afraid to make things worse?
- Did you get lucky or was it strong teamwork and preparation?
- Review communication routes across the organization and identify any areas of improvement
- Was a team, manager, or department left in the dark?
- Did anyone critical for recovery not receive notification of the incident?
- What routes of communication were used?
- Is this the most effective method to communicate during an incident?
- Adjust incident management practices at a broader level to reduce impacts during subsequent incidents
- What went really well? Should this be incorporated into standard practice?
- What went badly? Should guards against this be incorporated into standard practice?
Ultimately, the goal of a post-incident review is to look at the entire sequence of events leading up to the incident. You want to not only identify what went well, but also investigate what didn’t go as planned so that the next time your team finds itself in this situation, they won’t make the same mistakes.
How Some Organizations do Post-Incident Reviews
Different organizations implement post-incident reviews in different ways. There really is no one way to conduct an incident review.
For example, Amazon and their contractors call their post-incident review root cause analysis or RCA. Amazon focuses less on the recovery and more on how to prevent the same incident in the future. Following a high severity event, RCA is completed within seven days and answers the five whys.
Amazon Web Services, or AWS, also publishes post-mortem event summaries following major service disruptions. Let’s consider the most recent major service disruption on December 10, 2021.
In their event summary, AWS admits: “impairment to our monitoring systems delayed our understanding of this event, and the network congestion impaired our Service Health Dashboard tool from appropriately failing over to our standby region. By 8:22 AM PST, we successfully updated the Service Health Dashboard.”

Make sure you can monitor your services because you don’t want to end up in the same situation AWS found itself in. You can continue to monitor services independent of any backend function when you use Instatus. Even if you have a critical failure on the backend, you will maintain access to your status pages.
If you want to view an example of how Google completes post-incident reviews, take a look at this example. While this was not a true outage or incident, it still provides value if you want to see how others navigate the post-incident review process. In this example, Shakespeare Search went down for 66 minutes when a new sonnet was discovered. The massive influx of users using a new term triggered a latent bug.
You can see the summary, impact, root causes, trigger, resolution, and detection outlined below.

Also, make note of the lessons learned section. Google highlights three key areas: what went well, what went wrong, and where we got lucky. Their monitoring system saved them in this case and the on-call was immediately notified.
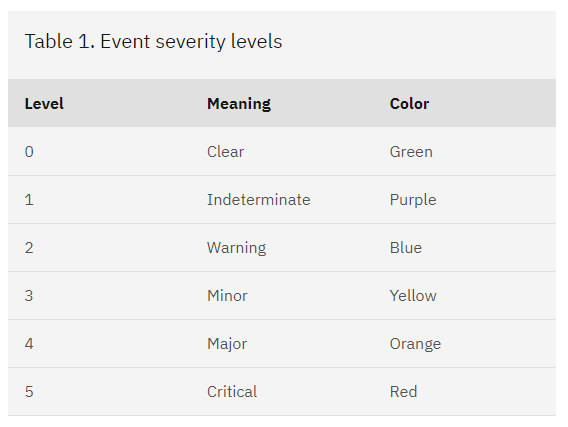
Finally, Google also makes a timeline of events. This allows management and team members to review what happened and when. The timeline notes when the outage and incident began and what each team member was doing.
If you incorporate this into your post-mortem review, you’ll gain a thorough picture of what happened during an incident and reduce any knowledge gaps.

Post-Incident Review Best Practices
It's important to handle post-incident reviews properly. You must create a safe space where everyone feels comfortable sharing their thoughts and ideas. Focusing on constructive discussions and learning from mistakes helps us improve continuously, which leads to a stronger and more effective processes.
**Establish a Culture of Accountability **
It's critical to provide everyone involved with the opportunity to speak freely about their involvement in the incident, their understanding of it, and its effects. This approach fosters transparency and helps uncover the true root cause of the incident. People may suppress important facts or assign blame if they are afraid of the repercussions, which damages team confidence.
Avoid singling out specific individuals as the only offenders at the post-incident review meeting and in any documentation that follows. Focus on acts, results, and implications instead to encourage a useful examination of the incident.
Include the Right People during the Review
Instead of keeping the circle narrow to minimize inspection, include all pertinent parties in a post-incident review (PIR). All key individuals who were involved in or witnessed the incident should be able to contribute their insights.
At the very least, the review should involve the incident managers and support staff who dealt with the problem, the problem manager responsible for finding the root cause, the service owner responsible for overall service assurance, and representatives from the affected business function.
Depending on the incident's nature, service provider representatives, communications staff, and even the user who initially reported the issue might also be included in the review to gather diverse insights and perspectives.
Review the Complete Timeline
When examining incidents, it's essential to consider that the incident's timeline starts when the business function or user initially encounters the impact, which may be before the official logging and declaration of the ticket. Therefore, when conducting incident reviews, it is essential not to focus solely on the events that occurred after the ticket was opened.
To address this, we can ask specific questions during the PIR to focus on the early incident stage and uncover opportunities for enhancement:
- When did the impact on the business truly start?
- How did you become aware of the issue? Was it reported through the helpdesk, or did automated systems detect it?
- How much time passed before you recognized and confirmed it as an incident?
- Did you need to escalate the situation? How well did the escalation process work?
- Were there any challenges in getting support staff involved, like identifying the right contacts or ensuring their availability?
Assess the Use of Data and Tools for Analytics and Diagnostics In order for subject matter experts to successfully analyze and diagnose underlying issues during incident troubleshooting, they must have access to the proper tools and data. The team must evaluate the information and resources that were available and utilized during the post-incident review, as well as those that they wish had been available, to make the process simpler.
The PIR can aid in revealing these hidden resources, ensuring that the staff is aware of them and is able to access and utilize them efficiently in the event of further accidents. By providing our staff with all the resources they require to be successful, we can improve incident resolution.
Keep The Critique Constructive While maintaining a safe and objective discourse is important, a good resolution requires identifying the incident's underlying causes. Don't allow the discussion to sidestep painful facts or opt for a simple consensus only to steer clear of challenging subjects. We open the door for true solutions and avoid the recurrence of the same challenges by fearlessly confronting the real concerns.
Implement a systematic decision-making process During incidents, there's a lot of stress and pressure to restore services quickly. Many decisions need to be made on the spot, like classifying the impact, deciding who to communicate with, choosing troubleshooting paths, and taking action steps.
Any team member has the right to make some decisions on their own. However, some decisions ought to be decided by a committee or a person in a position of authority. Looking back at the choices made during the incident and how they were made is a great opportunity provided by the post-incident review (PIR). By doing this, future misunderstandings about power and the decision-making process are reduced.
**Examine every Post-Incident Review ** After creating a post-incident review, it's crucial to actually review it to address any lingering problems, record valuable ideas for the future, and complete the report. A helpful practice is to set up regular meetings, maybe monthly, involving engineering and other relevant parties like customer support or account managers. In these meetings, you can go through recent or older reviews and share important lessons and insights. This way, you ensure that the review process remains thorough and effective in improving future incident responses.
A Template you Can Follow for Post-Incident Reviews
So now you’ve got an idea of how other organizations are conducting their post-incident review process, let’s take a look at a sample review template. Feel free to adjust this template to suit your needs.
Incident:
Date of Incident:
Summary:
Review Goals:
- Your #1 goal
- Your #2 goal
- Your #3 goal
Incident Severity: Use rankings(1-5 is common)
Customer Impact (Quantifiable): How many customers were impacted?
Incident Commander/Manager:
Time Incident Started:
Time to Acknowledge Incident:
Time to Recover:
Who received the initial alert:
Which departments, parties, and individuals were notified:
Was external help needed from other departments or contractors:
List of tasks completed:
Which tasks helped recovery:
Which tasks hurt recovery:
Timeline: Timestamp each action, important communications, etc
Lessons Learned:
- What went well?
- What went badly?
- Was there any luck?
Factors that contributed to the incident:
Any Recommendations to Practice or Process Changes:
How to Conduct a Post-Incident Review
There are general rules that can help you conduct a great post-incident review. Try to incorporate as many of these best practices as possible and the quality of your reviews and results will improve.
- Who is conducting the review?
Many organizations opt to use a third-party facilitator for the post-mortem process. If the team responsible for response and recovery is conducting the review, then bias may impact the report. It’s human nature to judge yourself and your actions in a more positive light. You can limit the impact of confirmation bias and hindsight bias using a facilitator. They will be able to objectively research, study, and draw conclusions about the incident.
The key to using a facilitator is to have a no-blame culture. Your team will operate under a fear of failure and of being called out if there is constant finger-pointing. Avoid terms like ‘human error’ and instead create an open conversation around mistakes. No one should be getting in trouble when a mistake causes a critical incident.
Additionally, management should be fully engaged during the review process. When management checks out early, this is a signal to the team that learning does not have value or priority in your organization.
- Establish a Timeline
The timeline of events is going to be the best way to understand how the incident unfolded. Maybe your timeline shows that 20 minutes went by before the IT department got a notification of the incident because of a missing metric trigger or maybe your timeline shows that the scope of the incident was originally misdiagnosed because vital monitoring systems were lacking.
When establishing a timeline, you want to interview everyone. Each perspective may reveal another data point that is important to understand what happened that day. If you only interview a handful of people, you may miss an important perspective.
For example, maybe engineer John Doe tried to recover the system 10 minutes before Jane Smith who wasted time in this recovery attempt since John Doe had already tried this method. However, since there was a lack of communication, she was not aware of this fact. If you don’t interview John Doe, you may never realize there was a breakdown in communication.
- Identify Metrics
Metrics are everything when it comes to prevention and understanding. Quantify as much as you can and you will have sufficient information to draw conclusions and make recommendations for the future.
You want to be transparent to customers and investors. Outages are going to happen, but your organization has a responsibility to keep your customers informed. You can provide real-time updates about your services by using status pages like those provided by Instatus.
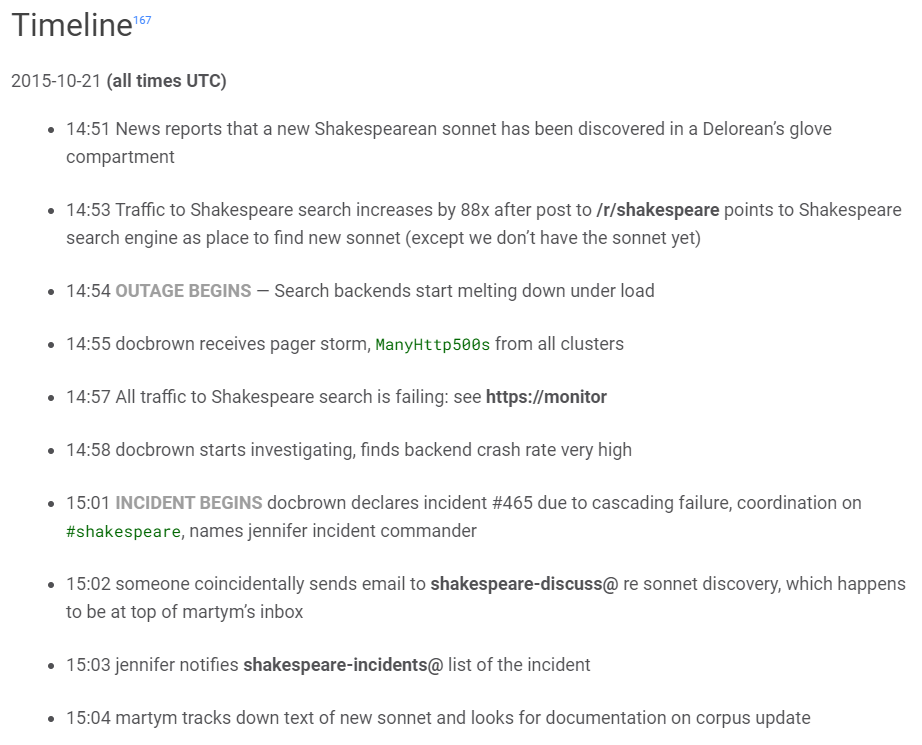
Most organizations will quantify the severity of an event based on the impact to customers. For example, IBM uses six different severity levels. During Sev1 or Sev2 incidents, the general reaction is all hands on deck. Even those not directly tied to the incident may provide support, expertise, or assistance to ensure recovery.
Metrics can help track incident management responses over time. For example, perhaps your Mean Time to Acknowledge (MTTA) and Mean Time to Recover (MTTR) has seen a 10% decrease over the last 12 months. This tells you your post-mortem is effective in helping your team learn how to handle incidents better.
Defining the End Results
If your organization is not doing post-incident reviews, it’s time to ask why. Post-incident reviews create a culture centered around continuous improvement and learning how to do better. Doing so will also help team members feel empowered to make changes and learn from mistakes.
Instead of feeling down about an outage and failure, the conversation should focus on how to prevent such incidents from happening again in the future. Your customers will greatly appreciate the hard work and will be thankful for a decrease in incidents.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers