
Reliability Engineer Explained: Role, Goals, & Techniques

Helpful Summary
- Overview: Reliability Engineers (REs) are critical to IT operations., They focus on system performance and stability. Their core tasks include tracking performance metrics, automating solutions, and minimizing downtime. The article outlines their roles, goals, and the importance of their expertise.
- Why you can trust us: Instatus provides top-tier monitoring tools that are trusted by numerous clients to maintain high system reliability. Our case studies showcase significant improvements in uptime and user satisfaction, highlighting the effectiveness of their tools in real-world scenarios.
- Why it matters: Reliability engineering can significantly enhance system reliability, reduce costs, and improve safety. It ensures fewer unexpected failures, optimizes resource use, and extends product lifespans.
- Action points: Hire a RE to optimize your IT operations. Focus on automating repetitive tasks and monitoring performance metrics to reduce downtime and improve user experiences.
- Further research: Explore resources like Google’s SRE Ebook and DevOps integration strategies to complement and enhance your understanding of reliability engineering.
Companies that are concerned with the stability and reliability of their infrastructure and services have happier customers. If your SaaS software is plagued with service disruptions it may be time to address the issue head-on – consider taking your credibility to the next level by hiring a reliability engineer. In the meantime, build user trust during outages or service disruptions by incorporating a user-friendly informative status page with Instatus.
Despite a hefty salary tag, a reliability engineer provides invaluable IT operations expertise to your company. A good RE will optimize equipment effectiveness and improve system performance and stability. Continue reading to learn more about the roles, goals, and techniques of reliability engineers.
Why Listen to Us?
Reliability engineering is essential for maintaining system performance and preventing downtime. Instatus has helped numerous businesses monitor any incidents.

Our customers have seen significant improvements in system reliability. For example, Etsy enhanced product quality and customer satisfaction by integrating continuous testing into its DevOps practices. Another client, Netflix, ensures it’s responsive to market changes by continuously testing to manage multiple daily deployments.
By addressing these pain points, our customers have benefited from reduced defect-related costs and improved customer experience. To these clients, the importance of effective reliability engineering in today’s digital landscape can’t be overstated.
What is Reliability Engineering?
Reliability engineering is a subfield of engineering focused on improving equipment reliability. This engineering field is most common in the manufacturing, production, and information technology spaces. This article is concerned with reliability engineering as it relates to IT operations.
Site Reliability Engineering (SRE) applies software engineering principles to information technology operations. SRE is a specific branch of reliability engineering coined by Ben Treynor Sloss, now VP of Google Engineering.
Sloss introduced the concept of SRE in late 2003, shortly after joining Google, and when he began leading a team of 7 engineers to solve IT issues that system administrators were handling. Check out Google’s Ebook on SRE to learn more about their experiences and successes.
Before Site Reliability Engineering, there was minimal communication between software engineers/developers and the IT department. The software was developed independently without consulting IT professionals. A finished project was then handed off to the IT team responsible for building systems to suit the project. IT handled deployment and maintenance and was responsible for managing any downtime or unforeseen production issues.
The concept of SRE has spread widely throughout the software development industry. There are currently over 210,000 open positions listed for ‘Site Reliability Engineer’ on LinkedIn in the United States. Companies of all sizes are starting to incorporate this role into their teams where possible.
What is the job description of a Reliability Engineer?
Job description summary
The understanding of component, equipment, and process reliability is the primary focus of a reliability Engineer. This entails developing and utilizing a range of analysis techniques to rate their effectiveness.
To find reliability difficulties, data is gathered and carefully evaluated. Diagrams, charts, and reports are then used to illustrate the findings and make improvement suggestions. Investigating individual dependability issues and selecting the best course of action while taking into account things like equipment uptime, repair costs, and material availability are also part of the task.
Action plans are created to provide dependable processes and equipment, reducing the risk of failures by analyzing various solutions and taking customer requests into account.
Education
Typically, candidates must hold a bachelor's degree in engineering or a closely related profession. The typical fields of study for this position are mechanical or electrical engineering. However, there are also options for applicants to participate in apprenticeships, which provide beneficial instruction and practical experience to help them get the job done.
Experience
Numerous entry-level roles are available in the field of reliability engineering, some of which may simply call for 0–2 years of experience. But depending on the job description, a little bit more experience or particular certifications can be required for some tasks.
Candidates with industry-specific knowledge may also be sought after by some employers. Such circumstances make prior job experience valuable, making internships or work placements advantageous for obtaining relevant knowledge and distinguishing as a great applicant.
Roles and responsibilities
-
The reliability engineer collaborates with project engineering to guarantee the dependability and simplicity of maintenance of new and updated installations.
Their main duty is to ensure that these new assets operate effectively and continue to be dependable over time by adhering to the life cycle asset management (LCAM) approach for the entirety of their lives.
-
Actively participates in the development of commissioning plans as well as design and installation specifications.
They contribute to the creation of standards for rating tools, technical suppliers, and maintenance service providers. In order to make sure everything complies with the necessary standards, they are also in charge of devising acceptance tests and inspection criteria.
-
Takes part in the final check-out of newly installed equipment.
To make sure that everything complies with the functional requirements and standards, this entails performing both factory and site acceptance testing. Before they are placed into full operation, the new installations are to be checked to make sure they adhere to the appropriate requirements.
-
Oversees efforts to guarantee the dependability and ease of maintenance of all tools, utilities, facilities, controls, and safety/security systems.
They give direction and supervision to ensure that everything runs efficiently and safely, reducing the possibility of breakdowns and interruptions.
-
Establishes, designs, and improves an asset maintenance strategy in a professional and systematic manner.
The plan comprises beneficial preventative maintenance activities that raise the asset's value. Additionally, they find and fix any reliability faults in the assets using efficient techniques like predictive and non-destructive testing.
This strategy aids in ensuring that the assets run effectively and with little downtime.
-
Provides insightful contributions to a risk management approach. Both reliability-related and non-reliability-related issues that can adversely affect plant operations are identified and foreseen with their assistance.
By doing this, they significantly contribute to the proactive resolution of prospective problems and the smooth and effective operation.
-
Creates engineering solutions for issues like recurrent failures and any other issues that have a negative impact on plant operations.
-
Offers technical assistance to management and technical staff in manufacturing and maintenance. Works with Production to analyze assets, including their effectiveness, utilization, remaining useful life, and other factors defining their condition, reliability, and costs.
What is the role and the goals of a Reliability Engineer?
A reliability engineer solves operations problems with engineering work. To meet this goal, SREs are responsible for tracking and monitoring latency, performance, availability, and other metrics for their sites and services.
Interestingly, reliability engineers meet these responsibilities by building tools and services that reduce the operations workload. Reliability engineers are expected and rewarded for fixing issues and then finding a way to automate that fix.
According to Google’s Director of SRE Dublin, Dave O’Connor, the best reliability engineers are regularly automating themselves out of a job. His engineers are lazy, therefore when they identify a problem, they solve it and find a way to automate the solution so that they don’t need to revisit that issue again.
Site Reliability Engineers develop the IT systems to be reliable, automated, and scalable to suit the business's needs. The SRE skillset differs from traditional software developers. SREs need a thorough understanding of monitoring, logging, configuration management, metrics, and automation.
SRE vs DevOps?
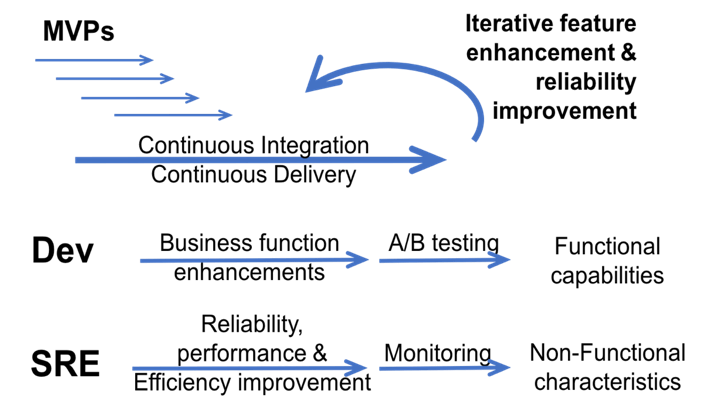
DevOps is another methodology for handling software development and IT operations. DevOps surfaces as a new software development methodology in 2008 and has gained significant traction. DevOps is the combination of ‘development’ and ‘operations’.
Despite some overlap in principles, DevOps is not the same as SRE. DevOps is primarily focused on developing a core product. DevOps is working to involve IT systems development with the software design.
At the same time, Site Reliability Engineers are more focused on minimizing downtime, automating IT operations, and reducing the workload of system administrators. SREs will engage the primary development team to provide feedback on IT systems integrations that are not working as intended.
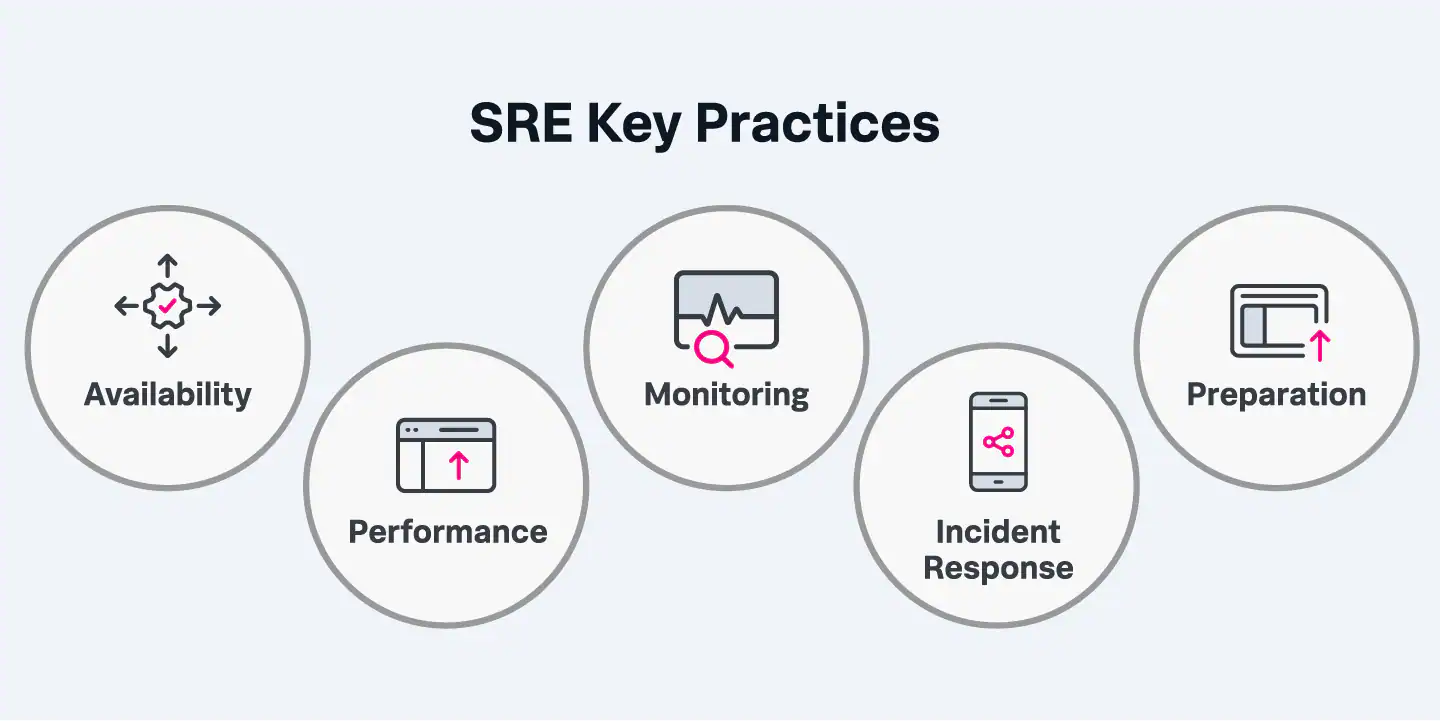
DevOps and SRE are non-competing methodologies. Any Site Reliability Engineering team will benefit if the primary software development team incorporates DevOps principles because the team will be more IT aware during development.
What techniques does a Reliability Engineer use?
Reliability Engineers cannot do their job without data. REs rely on tools that collect data from the application for monitoring and analysis. Once the data has been analyzed, SREs can develop actionable areas to improve IT performance and user experiences. Some of the techniques that reliability engineers incorporate are:
1. User Experience
The most important goal for REs is to increase uptime and limit service disruptions. This involves understanding which services are more valuable and popular with users.
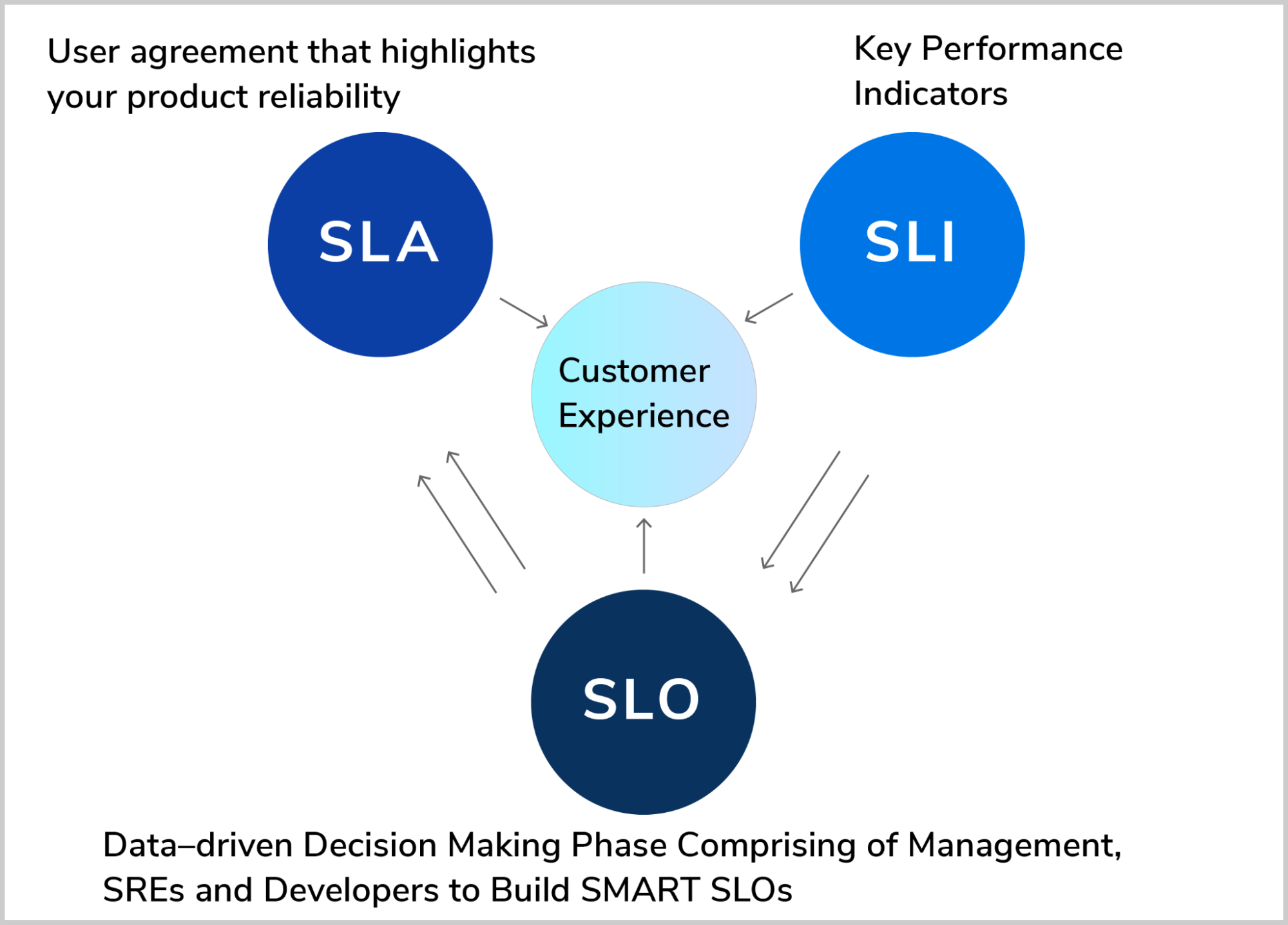
Site Reliability Engineers use SLIs or Service Level Indicators to provide a quantitative value to a specific service or feature. SLOs or Service Level Objectives is the preferred value or target being measured by SLIs.
The most classic and typical example of SLIs and SLOs is availability. If users are happiest with an uptime of 99.5%, your availability SLO is set to 99.5%. The actual uptime metric is the SLI measurement. Maybe it’s 99.25%, so your SRE understands there is room to grow in this area.
2. Change Management
Change is the friend of SREs, but can also cause significant issues and downtime if not appropriately managed. Most unexpected outages can be attributed to a change made without proper management.
Up to ‘80% of unplanned outages are due to ill-planned changes made by administrators (‘operations staff’) or developers’ according to IT Process Institute’s Visible Ops Handbook. Human error is costly and SREs are focused on reducing this impact.
SREs will develop precise procedures for rolling out changes, planning downtime, using version control, and necessary rollback steps. Outage procedures will also incorporate incident management principles so that the affected users are notified quickly and efficiently. Removing manual deployment of updates is one of the best methods to reduce unplanned outages.
3. Automate Everything
The value of automation is enormous for Site Reliability Managers. When processes or services are developed using automation, there is a higher level of consistency, less labor needed, and a quicker recovery. SREs that integrate automation into their systems will save time and labor each time that automated tasks are executed. Usually, automation is a positive feedback loop that dramatically improves uptime and user experiences.
4. Standardize Tools
Standardizing the SRE toolset is a must for any organization. This standard will differ across different organizations. If you run an eCommerce application, you may be incorporating a different group of tools than if you are responsible for a social media application. Regardless of the specific tools, most teams will need the following type of tools:
- Application Performance Management & Monitoring
- Real-Time Communication
- Configuration Management
- Automated Response Systems
5. Blameless Culture
Successful SRE teams don’t play the blame game. Understandably it’s disappointing when someone’s mistake leads to costly downtime, but blaming that individual creates a culture of fear.
A culture of fear often breeds a culture of stagnation. It’s best to assume that the engineer made the best decision possible with the information they had access to at that time. The downtime costs can be recuperated more quickly than a damaged team culture.
Instead, the postmortem incident record should be used as a learning experience. The team now knows a failure method and can focus on building a solution to prevent this failure again.
Benefits of Working with a Reliability Engineer
Here are the major advantages of working with a RE:
Increased System Reliability
REs improve system reliability through design optimization and predictive maintenance. They identify potential failure points and optimize designs using tools like Failure Modes and Effects Analysis and Reliability Block Diagrams.
Cost Reduction
A RE helps reduce unexpected failures, minimizing downtime and associated costs. Predictive maintenance and optimized designs also help organizations better take advantage of their resources.
Safety Improvements
REs critically enhance safety by identifying and addressing potential failure modes. They also help organizations avoid legal and regulatory issues.
Extended Product Lifespan
Through durability analysis, REs determine the longevity of components and systems. This helps extend the product's lifespan with better materials and designs.
Data-Driven Decision Making
REs rely on data from field performance, warranty claims, and testing to make informed decisions about design, manufacturing, and maintenance processes. They implement key performance indicators (KPIs) related to reliability, aiding in monitoring and continuous improvement efforts.
Reliability Engineers vs. Maintenance Engineers
There are key differences between REs and maintenance engineers. Here are the main differences you should know about:
- Proactive vs. Reactive: REs prevent failures through design optimization and predictive maintenance. They aim to foresee and address potential issues. Maintenance engineers instead handle immediate repairs and routine maintenance. They also respond to equipment issues as they occur to ensure continuous operation.
- Long-term vs. Short-term Focus: REs are focused on the long-term goals of improving the overall reliability and lifespan of systems. Maintenance engineers address short-term needs, ensuring equipment functions correctly through regular servicing and immediate issue resolution.
- Analytical vs. Hands-on: REs use analytical tools like statistical analysis and reliability modeling to predict and enhance system reliability. On the other hand, maintenance engineers perform inspections and repairs, and manage spare parts to keep equipment in excellent condition.
- Design Involvement vs. Operational Focus: REs ensure reliability is built into products from the start. They are involved in the design and development stages. Maintenance engineers focus on the operational phase instead. They maintain and repair existing equipment to ensure smooth and efficient operations.
Predictive Maintenance vs. Preventive Maintenance: REs develop predictive maintenance schedules based on data analysis to forecast when maintenance should be performed. Maintenance engineers focus on preventive maintenance through regular inspections and servicing to prevent future breakdowns.
What tools does a Reliability Engineer Use?
Reliability engineers use various tools to manage the systems, applications, devices, and servers they are responsible for. There are endless options available in the market for automation and software tools to aid SREs in their job, but these are some of the popular tools:
Application Performance Management & Monitoring Tools
Application Performance Management (APM) software is used to manage the performance of an application. APM tools provide usage and performance data, server metrics, framework metrics, logging data, plus custom metrics. Application Performance Management tools are budget-friendly and should be adopted by businesses of all sizes.
Take a look at some of the top APM and monitoring tools in the Site Reliability Engineering space:
Instatus
Key Features
- Status Pages: Instatus offers customizable status pages to display the operational status of services.
- Incident Management: Tools to report, update, and resolve incidents efficiently.
- Uptime Monitoring: Basic monitoring to track service availability and performance.
Datadog
Key Features
- Application Performance Monitoring (APM): Provides code-level distributed tracing to monitor application performance from the front-end to back-end.
- Infrastructure Monitoring: Offers real-time observability of infrastructure metrics across various cloud services.
- Log Management: Centralizes log data for easy querying and analysis.
New Relic
Key Features
- APM: Offers detailed performance monitoring and root cause analysis with distributed tracing.
- Infrastructure Monitoring: Monitors infrastructure health and performance metrics.
- Log Management: Centralizes log data for analysis and troubleshooting.
Prometheus & Grafana
Key Features
- Time-Series Data: Prometheus stores time-series data, providing powerful querying capabilities.
- Alerting: Configurable alerting rules to notify teams of potential issues.
- Dashboarding: Grafana offers customizable dashboards to visualize metrics and performance data.
Automated Response Systems
Automated Response Systems (ARS) are incident response systems that will automatically notify any SREs on-call in case of a failure. Following Lowe’s incorporation of SRE principles including an automated incident response system, the number of releases increased dramatically. The Site Reliability Engineers are able to push over 20+ releases a day and have decreased MTTR (mean-time-to-recovery) by an astounding 80%!
Pager Duty
Key Features
- Incident Workflows: PagerDuty allows the creation of custom incident workflows to automate repetitive steps in the incident response process.
- Event Orchestration: Event Orchestration helps in enriching, modifying, and routing events based on specific conditions by automating diagnostics and remediation tasks.
- Runbook Automation: Facilitates the delegation and execution of predefined automation jobs. It connects incident responders with automated tasks for diagnostics, triage, and remediation.
Ops Genie
Key Features
- Incident Automation: Automates the incident response process by integrating with monitoring tools. It minimizes response times and ensures that the right team members are promptly alerted.
- Alert Enrichment and Correlation: Enriches alerts with relevant context and correlates similar alerts into single incidents.
- On-call Scheduling: Automates the rotation of on-call duties and ensures that incidents are always assigned to the available and appropriate personnel.
Real-Time Communication
Use messaging software to keep the SRE team in constant communication with each other, the primary development team, IT professionals, and business leaders. Slack is the most popular real-time communication program in the software development space. There are many other great options, including Microsoft Teams and Amazon Chime.
Slack
- Instant Messaging: Facilitates real-time text communication between individuals and within teams, enabling efficient collaboration.
- Voice and Video Calls: Allows users to initiate audio and video conversations directly within the platform for more personal and immediate communication.
- Screen Sharing Capabilities: Enables users to share their screens during a call, making it easier to present information and collaborate on tasks in real-time.
Microsoft Teams
- Integrated Chat Functionality: Supports real-time text conversations which enables users to communicate instantly in one-on-one or group settings.
- Video Conferencing and Voice Calls: Provides robust tools for conducting virtual meetings and voice calls, ensuring seamless real-time communication and collaboration.
- Real-time Collaboration on Documents with Integrated Office 365 Apps: Allows users to work simultaneously on documents, spreadsheets, and presentations directly within Teams to enhance collaborative efficiency.
Amazon Chime
- Video And Voice Conferencing: Offers high-quality audio and video calls, ensuring clear and reliable communication during meetings.
- Instant Messaging With Persistent Chat Rooms: Supports real-time text communication with features for ongoing chat rooms and one-on-one messages to maintain continuity in conversations.
- Screen Sharing And Remote Control: Allows participants to share their screens and even grant control to others, facilitating interactive and collaborative discussions in real-time.
Configuration Management
Configuration management is the process of maintaining systems, servers, and software in a consistent configuration. If you know how a design will perform with a specific configuration, you want that configuration applied across all systems within the organization. Mismatched configurations can lead to downtime and performance issues.
For example, there should be no differences in server configurations for a specific service. Configuration management will identify the systems that are out of configuration and recommend the correct configuration or patching if necessary.
Ansible
- Agentless Automation: Ansible operates without installing agents on managed nodes. This simplifies the setup and management of automation tasks across infrastructures.
- Playbook-based Orchestration: Uses YAML-based playbooks to define automation tasks, allowing for configuration management, application deployment, and orchestration across servers.
- Extensible Through Modules: Offers a wide range of modules that extend functionality, enabling integration with various systems for seamless automation and management.
Chef
- Infrastructure as Code (IaC): Chef enables infrastructure configurations as code, allowing for consistent deployment and management across environments.
- Chef Recipes and Cookbooks: Uses Ruby-based recipes and cookbooks to define configurations and policies, facilitating automation of infrastructure setup, configuration, and management.
- Integration with DevOps Toolchain: Integrates with CI/CD pipelines and other DevOps tools, enabling automated testing, deployment, and management of infrastructure and applications.
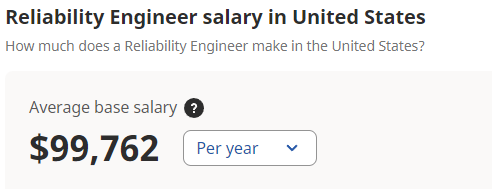
What is the salary of a Reliability Engineer?
According to Indeed, the average base salary of a Reliability Engineer in the United States is $99,762. This salary is artificially low because it includes Reliability Engineer roles for facilities and manufacturing environments.
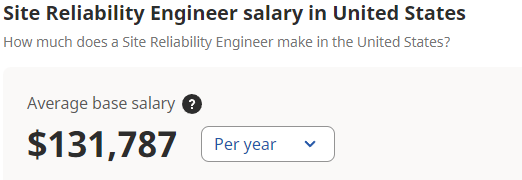
Comparatively, the average base salary for a Site Reliability Engineer in the United States is $131,787. Experienced SREs can easily command salaries in excess of $200,000.
If you are looking to hire a Site Reliability Engineer, be aware of your competitor's offers. Smaller companies may opt to hire under the job title of Reliability Engineer to reduce costs but expect a talent drop.
Incorporate Site Reliability Engineering With DevOps
SRE and DevOps are a perfect pair. If your software development team is already integrating DevOps principles, it will be a natural extension to add Site Reliability Engineering. Before these methodologies, information technology was considered an afterthought. Product development timelines and service uptimes will improve by centering development around IT systems.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers