
Mean Time Between Failures: Comprehensive Guide

Modern software relies on many moving parts, and if everything doesn’t go just right, you can have partial or critical failures. Yet users expect a high-quality software product with limited downtimes. So how do you limit downtimes and keep users happy? Well, metrics, of course.
Using the Mean Time Between Failures metric, you can predict the time between software failures. If your failures are too frequent and your team focuses on increasing MTBF, start by ensuring your users stay updated on any ongoing issues with Instatus. Without a status page, users get left in the dark during outages.
What is Mean Time Between Failures (MTBF)?
Mean Time Between Failures, or MTBF for short, is an incident metric measuring the time between each failure incident. MTBF is closely related to other incident failure metrics, including MTTR and MTTF. We’ll briefly cover these metrics later. For now, you need to know that MTBF will tell you in calendar time the average calendar time between each software failure.
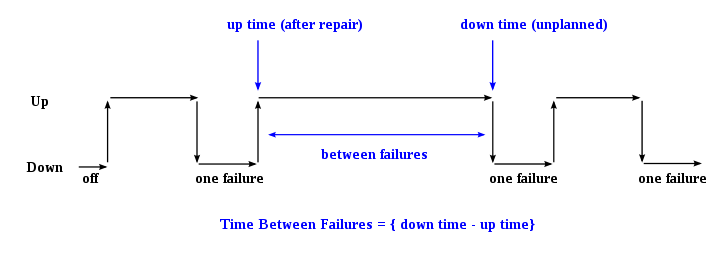
You can use this information to predict when your team’s next failure event will occur. Reliability is the ultimate test for your software. You want to design and build a system with high reliability, failing infrequently and predictably.
A low MTBF suggests your software product is unreliable and needs further work to improve stability. While a high MTBF means your development and deployment process is working well and not introducing any instability issues.
What is a Failure?
Your organization needs to define what a failure is before you can calculate MTBF. Do you want to count any and all incident events, even partial failures like a single service going down? Or do you want to only count complete failures?
You can even calculate two MTBF values. One to measure the mean time between complete operational failure of the software product and the mean time between partial failures. The choice is yours, whoever you think provides more value to your organizational goals.
Generally, do not count any scheduled preventative maintenance as a failure event. Scheduled maintenance is common in the gaming industry, where the players need are booted from the servers for updates.
How to Calculate Mean Time Between Failures?
Calculating Mean Time Between Failures is simple. Determine the number of operational hours and divide by the number of failures experienced during this time period. The mean time to failure formula is below:
# of operational hours / # of failures = Mean Time Between Failures (in hours)
Let’s look at the following example:
A software product has been operating for 4,000 hours (roughly 6 months). During that time, this product experienced 8 failures. MTBF for this product is calculated as:
4000 hours / 8 failures = 500 hours between failures (about 21 days).
Combining MTBF and MTTR
Mean Time to Resolution (MTTR) is the other half of the equation for determining your software product’s availability. MTTR is the average time your team takes to recover from an incident or failure. The availability target is often 99.99% uptime. To determine your expected downtime, you can combine MTBF and MTTR, continuing with the same example:
-
The MTBF value calculated earlier was 500 hours between failures.
-
Next, to calculate MTTR, take the total downtime (in minutes) / # of failures. For this team, MTTR is 120 minutes across 8 failures. Their MTTR is 15 minutes.
-
To calculate your availability over the last 6 months, use the following availability formula:
**(1 - (MTTR/MTBF)) x 100% = Availability **
Plugging in the numbers for this example team:
(1 - (15/500)) x 100% = 97%
This team is 2.99% from the 99.99% uptime goal.
-
Let’s go one step further and calculate the expected downtime over the next 30 days (720 hours) using the following equation:
(Time period/ MTBF) * MTTR = Expected Downtime
Convert all values to minutes to give a final value of downtime in minutes.
(43200 minutes/ 30000 minutes) * (15 minutes) = 21.6 minutes Expected Downtime
Using these equations, you learn a lot about your team’s performance and how to plan for downtime and outages. If these values are outside your goals, you need to increase MTBF or lower MTTR.
Improving Mean Time Between Failures
If your team is falling short in the MTBF area or other associated metrics like availability or expected downtime, then it’s time to take action. You can increase your MTBF by incorporating some of the points below:
1. Root Cause Analysis (RCA)
Why is your software failing? Before you can increase MTBF, you need to understand what kind of events are happening and why they are happening. As part of your incident response plan, root cause analysis is usually the last step. Root Cause Analysis, or RCA, helps you discover what caused your software to fail.
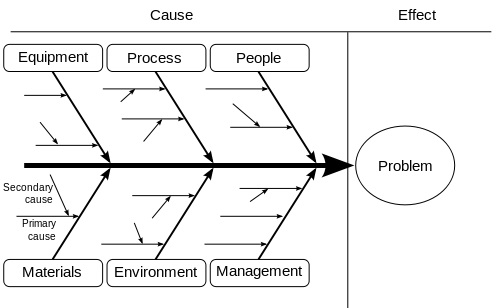
Typically you will identify the failure as one of the following ‘misses’:
- Testing miss
- Development miss
- Design miss
- Deployment miss
Once you determine that the failure occurred due to a testing miss, for example, you can move on to why the testing miss happened. Ask more questions about your testing processes and where the weaknesses are. Identify ways to improve your processes and prevent this situation from happening again.
2. Improve Stability
Focus on improving your operational stability if your software is frequently experiencing service crashes or other issues. Determine what is causing the instability. Is it a design flaw? Or is it a coding flaw? Rework that area of the software or services to prevent unnecessary failures. The more failures you can avoid, the longer your MTBF will be.
When stability is improved, and failures are limited, users spend less time checking out Instatus for an update on the current outage and more time using your product.
3. Standardize Processes
If you’ve identified that human error is causing your failures, it’s time to ensure that your developers know each process step. Standardize every process that your developers are involved in.
Let’s take code review, for example. When junior developers hand off their code to senior developers, is there a process in place? Or does every senior developer interpret code review in their own way? Do a few of your developers quickly glance over the code before sending it back without any comments. If so, you’ll get an inconsistent code review process, and things might get missed.
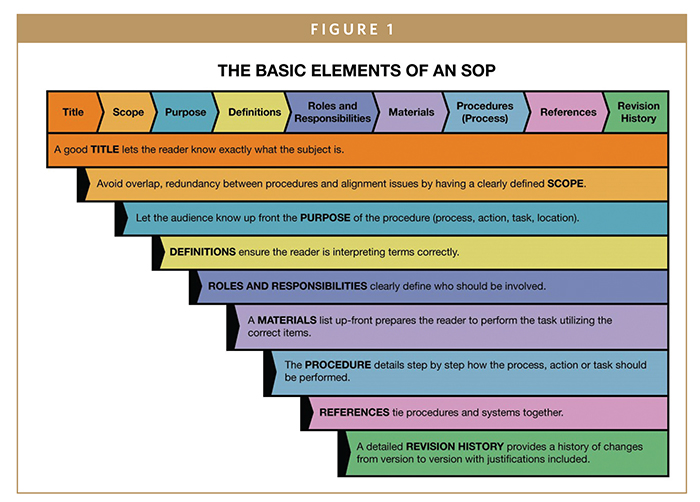
Instead, develop an SOP or standard operating procedure. With a standardized process, all code will be reviewed to the same standards, reducing the change for misses that lead to failure. A code review SOP may indicate the following requirements:
- Is the code formatted for readability? Are proper naming conventions used? Does the code contain sufficient comments to facilitate easy understanding?
- Is the code organized in a logical way? Are different pieces organized separately for clarity?
- Is there any hard coding? Multiple if/else blocks? Too much reliance on custom code? Are frameworks being used effectively?
- Does the code follow DRY principles? Are the functions and components reusable?
The senior developer will now work through the SOP when reviewing code. If indicated by the SOP, your developer will make comments and send the code back to the primary owner for edits. Then the process can repeat to make sure all issues were fixed.
To create your SOPs, try SOP software options like ProcedureFlow, Process Street, or Scribe.
4. Invest in Testing and Deployment Automation
Standardizing your main development processes is the starting point, but the ending point, more often than not is automation. Standardization may get you halfway there, but automation will take your team to the next level. So many organizations still opt to use manual methods for testing and deployment. At this point, it’s outdated and inefficient.
Testing automation tools offer excellent testing quality and are highly customizable. Check out Selenium, Katalon, or Appium to get started. AWSCodeDeploy, Jenkins, or GitLab are great options for deployment automation. When your team starts using automation tools, human error incidents will drop rapidly, and your team will reclaim much of their time to use for high-level dev work.
Wrapping up Mean Time Between Failures
Calculate the mean time between failures if you want to know how long your software is operational between failure events. Combine MTBF with metrics like MTTR, Change Failure Rate, and Deployment Frequency to understand how efficient and agile your team is.
Suppose your team is not meeting organizational expectations for MTBF. In that case, you can improve by finding the root cause for each failure, fixing software instability issues, standardizing your processes, and adding automation tools. Always keep your users briefed on failures and outages, using the beautiful status pages available at Instatus.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers