
What is Mean Time To Resolution (MTTR)? | A Guide to Incident Metrics

MTTR can be a canary in the coal mine that your incident management response plan isn’t working. Mean Time to Resolution or MTTR provides a great overall view of the reliability of your systems and how well your team is tackling outages.
These days, your incident management can make or break your business. With robust monitoring and reporting, you can quickly identify outages and restore service as quickly as possible. Use Instatus to keep your users updated on the status of your services so they are immediately aware of any issues. Within this guide, you’ll learn what MTTR is about and how to use MTTR and other metrics to better your systems.
What Is Mean Time to Resolution (MTTR)
Product or system failures are undesirable events. The primary goal behind incident management is to limit downtime incidents and reduce impacts to customers. Thankfully you can quantify your incident management with a handful of meaningful KPIs (key performance indicators). MTTR is a metric used to measure the average time required to find, diagnose, and fix an unplanned outage. Let’s take a deeper look into MTTR:
The ‘R’ in MTTR can be used for slightly different purposes. In this case, MTTR is the Mean Time to Resolution. In other words, it’s the average time it takes your team to return a system to fully operational status. MTTR does not directly measure other subsections of incident management, such as initial response time or delays.
Calculating Mean Time to Resolution
To calculate MTTR you can use a basic formula. First, you need to select the period of time you are interested in. Do you want to review MTTR for the entire calendar year, or do you want to check MTTR following incident management policy changes? Or do you want to check MTTR for the last week?
To determine MTTR you can use a basic formula:
Cumulative downtime / Number of Incidents = MTTR
Let’s imagine a period of 4 weeks. During these four weeks, your team experienced 4 outages. The cumulative downtime of these 4 outages was 3 hours. So your MTTR can be calculated as follows:
3 hours / 4 incidents = 0.75 hours per incident
Multiply 0.75 by 60 to get MTTR in minutes, meaning your team's Mean Time to Resolution for the last 4 weeks is 45 minutes.
When your system goes down, you can quickly update your users by using the notice feature provided with Instatus. To keep them in the loop, you can explain the issue that users will encounter and provide information like expected recovery times, to keep them in the loop.
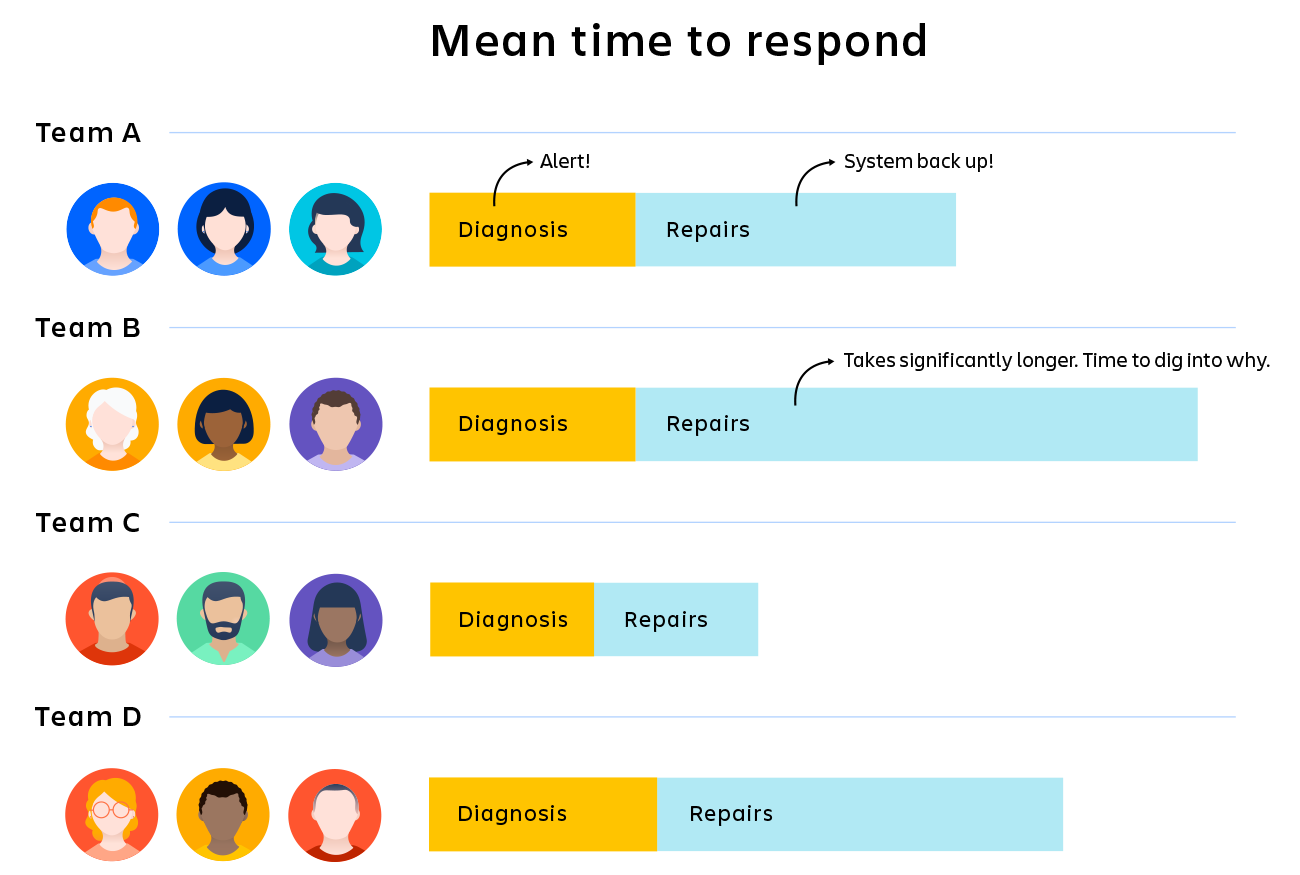
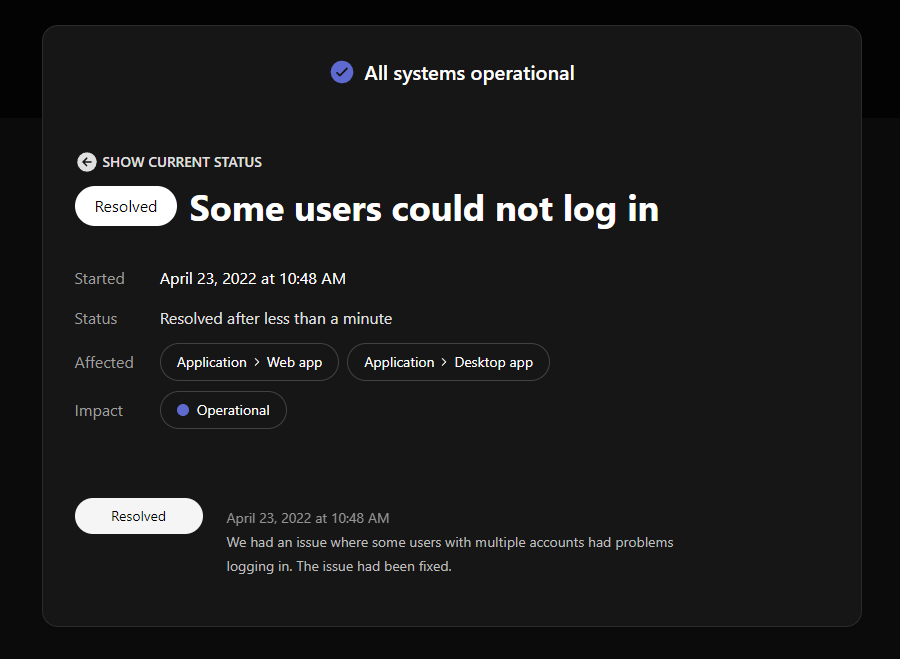
Mean Time to Recovery (MTTR) & Mean Time to Repair (MTTR)
Incident metrics aren’t standardized across the industry. Some teams use Mean Time to Recovery or Mean Time to Repair, which also use the MTTR acronym.
These metrics can be used interchangeably with Mean Time to Resolution. The MTTR formula found above is also used for these metrics. Essentially the variations in MTTR are limited to naming differences because all three metrics are measuring the same thing.
How to use Incident Metrics like MTTR?
Incident metrics provide your team with invaluable information on your incident management system. Do you know how your indecent management response plan stacks up? Businesses want ways to quantify every facet of their operations. KPIs in incident management provide critical information about how the system and team perform.
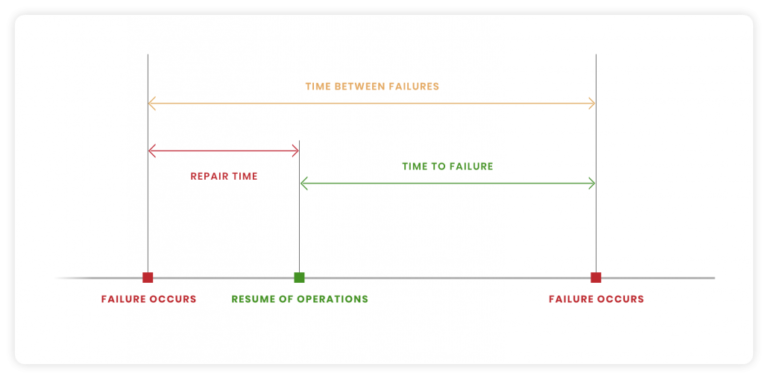
MTTR is a high-level metric that can quickly identify if your incident response plan meets expectations. MTTR cannot diagnose where the problems occurred along the incident timeline.
How to lower MTTR
Business leaders aren’t happy with the MTTR metric and want to see it lowered. You need to find out how to reduce MTTR. So what’s your game plan?
- Define ‘lower’
What do the incident management goals look like? Incidents happen all the time in this modern technical realm. Services go down, bugs crop up, and things break. Management may want zero downtime, but that’s wishful thinking. Instead, focus on challenging but reachable goals. This goalpost can move forward as your incident management response plan improves.
- Combine MTTR with Other Metrics
MTTR is a metric limited in scope. You will need other metrics that measure incident response to fully understand how your team is performing. We’ll briefly cover these metrics in the next section. Just know that additional metrics will provide a higher resolution of your incident response and help identify when and where the most significant barriers are.
- Identify the Issue
You can hone in on what section of the incident response plan is taking the longest by using multiple metrics. If response time is longer than the actual repair time, you are losing valuable time by not having proper monitoring and notification plans in place.
- Develop a Plan and Make Changes
Now you have the cause behind your elevated MTTR; you can develop a plan to address this problem. Institute organizational changes, add additional monitoring, hire contractors, and incorporate automation tools. With a new strategy in place, you are sure to lower MTTR.
Other Incident Metrics
MTTR provides an early indication that something is wrong, but you can use other metrics in conjunction to get a better picture of how your team is performing. Let’s briefly covers some of these metrics below:
Mean Time to Acknowledge (MTTA)
MTTA measures the average time between the first alert of an outage and when the team begins to address the issue. Does your team have an adequate alert system in place? Or does your team need to be more responsive when an alert comes in? Is there someone on-call during off-hours?
Imagine you have 5 separate system incidents. The total time to acknowledge is 2 hours. To find MTTA you divide 120 minutes by 5 incidents and will find that it takes your team, on average 24 minutes to respond to an incident.
If you quickly acknowledge an outage, you often exceed customers' expectations. Route them to status pages with Instatus, to alert them about the outage and what your team is doing to remedy it. Don’t force them to search your company’s social media pages for any indication that there’s an issue with their product.
Mean Time to Failure (MTTF)
MTTF or Mean Time To Failure can be a slightly niche metric. Not all systems and products will need to be measured with MTTF. MTTF measures the average time of complete non-fixable failures. If you provide a software product, this metric does not directly apply to your product. Software doesn’t fail due to wear or age like a car or computer will.
For example, Apple may measure the MTTF for each model of iPad. If they sell 100 iPads that last 2 years and 100 iPads that last 1 year, the MTTF would be calculated by summing the total number of years of operation and dividing that by the number of iPads. So Apple would have 300 years of operation divided by 200 iPads for an MTTF of 1.5 years. If consumers expect more than 1.5 years for the cost of the product, they will not feel the product is worth its cost and will take their business elsewhere.
Mean Time Between Failures (MTBF)
MTBF measures the average time between failures. In other words, it’s measuring the frequency of your outages. MTBF provides great information on the stability of your product. Mean Time Between Failures is also useful in predicting the overall availability of the product in the future.
To calculate MTBF, you need to know the dates and times of previous failures. If your failures occurred on 5/1, 5/5, 5/25, 6/10, and 7/1. Then you add up the days between failures, so 5+20+15+22 = 62. Now divide the days between failures by the number of failures, 62 days / 5 failures = 12.4 days.
Your MTBF would be 12.4 days. Is this meeting the expectations of the product? Is this meeting the needs of your customers? If the answer is no, you can now act on this data.
Combine with DevOps
When you combine incident response metrics with a DevOps mindset, your processes will improve overtime. Time is the recurring theme in incident metrics. When an outage or incident happens, it’s all about recovering as quickly and smoothly as possible. Use incident response metrics like MTTR to highlight problem areas your team is experiencing. Then begin continually improving and developing your incident response plan further.
Remember to keep your customers in mind during outages and alert them to outages immediately using status pages like Instatus. Incidents are never good for business, but when handled correctly, customers may gain respect for your brand, and you’ll be better able to handle the next event.

Get ready for downtime
Monitor your services
Fix incidents with your team
Share your status with customers